


Semi-Supervised Few-Short Learning Review
还在跑实验,正好有时间把最近看的一些东西放上来,主要是几篇有关SSFSL的工作
1. Meta-leanring for Semi-supervised Few-shot Classification
这是一篇ICLR2018的工作,主要贡献是定义了FSL中的semi-supervised问题,在Imagenet数据集上划分出子集tiredimagenet。
文章的思路很简单,主要基于PrototypeNet进行改进,结合半监督中聚类的方法,根据unlabel与prototype的相似度调整聚类位置。
生成新的prototype的方式使用了一个soft k-means来完成。
修改完的prototype为
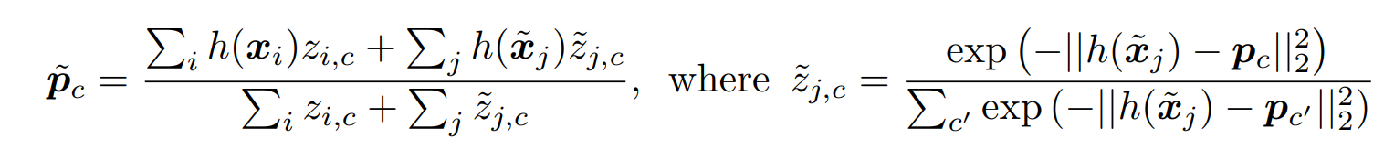
可以看出,后来的z是一个soft的权重,也可以理解成降噪
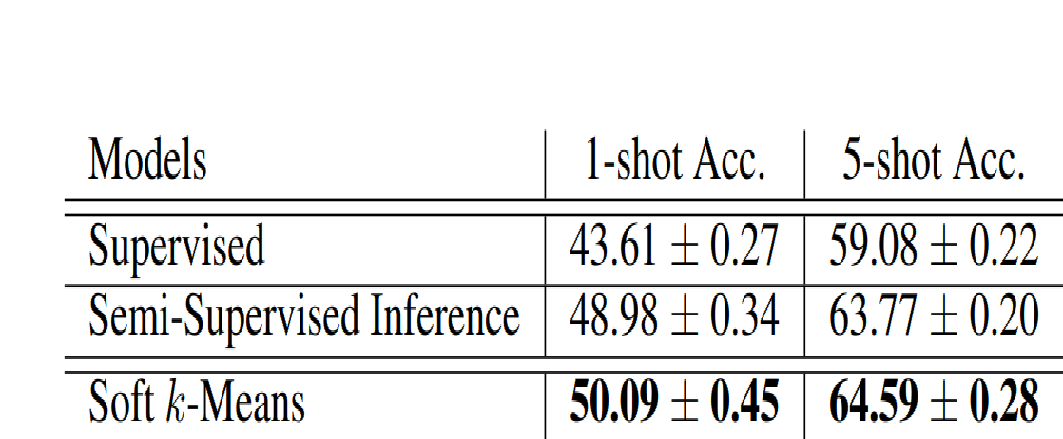
这里的supervised结果低是因为,在这个设定下,meta-train阶段的数据只有40%带标签。
2. Learning to Self-Train for Semi-Supervised Few-Shot Classification
一篇来自Nips2019的文章,从题目中就可以看出来是结合了semi-supervised中的self-train范式,并设计了一套挑选pseudo-label的方法。大体的流程如下
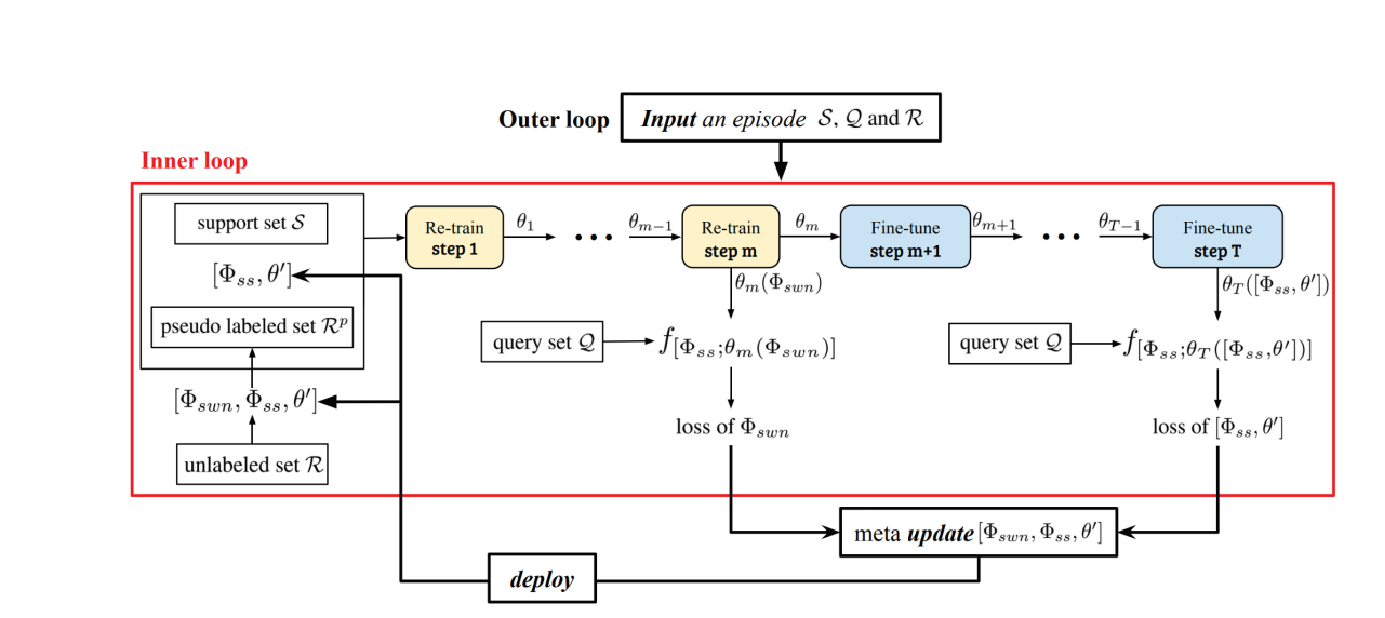
主要分内外两个循环,内循环针对没有个episode(task),外循环就是正常的meta-learning的范式。
在内循环中,可以看到有一个打标签的过程,其具体过程如下
思路也很简单,作者设计了两个策略,首先叫“hard selection”,其实就是挑选topk个保留。接下来是SWN,这个就是FSL中比较经典的工作RelationNet,使用这种方式来计算相似度,当作一个权重,加载pseudo-label上。
这里的结果是可以直接和supervised方法进行比较的,是因为meta-train阶段已经不是元学习了,是在所有base类别上进行train-all的,所以相比之下,多了额外信息,点数自然就高了。这篇工作是基于MTL来做的,点数比MTL高了不少。
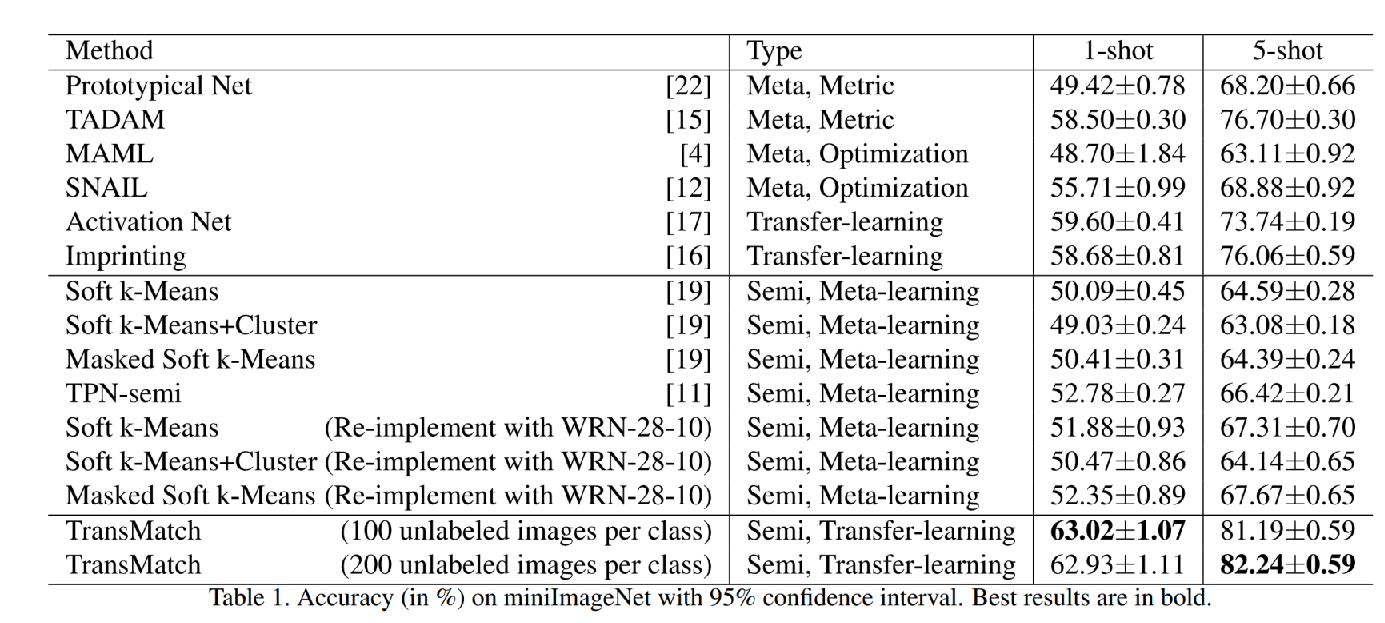
3. TransMatch: A Transfer-Learning Scheme for Semi-Supervised Few-Shot Learning
一篇CVPR2020的文章,创新一般,但是第一次显示提出用transfer-learning的范式来进行SSFSL学习。
首先还是pretrain一个特征提取器,之后初始化一个分类器的权重W,下一步就是用SS中一篇比较有名的工作MixMatch来进行学习。
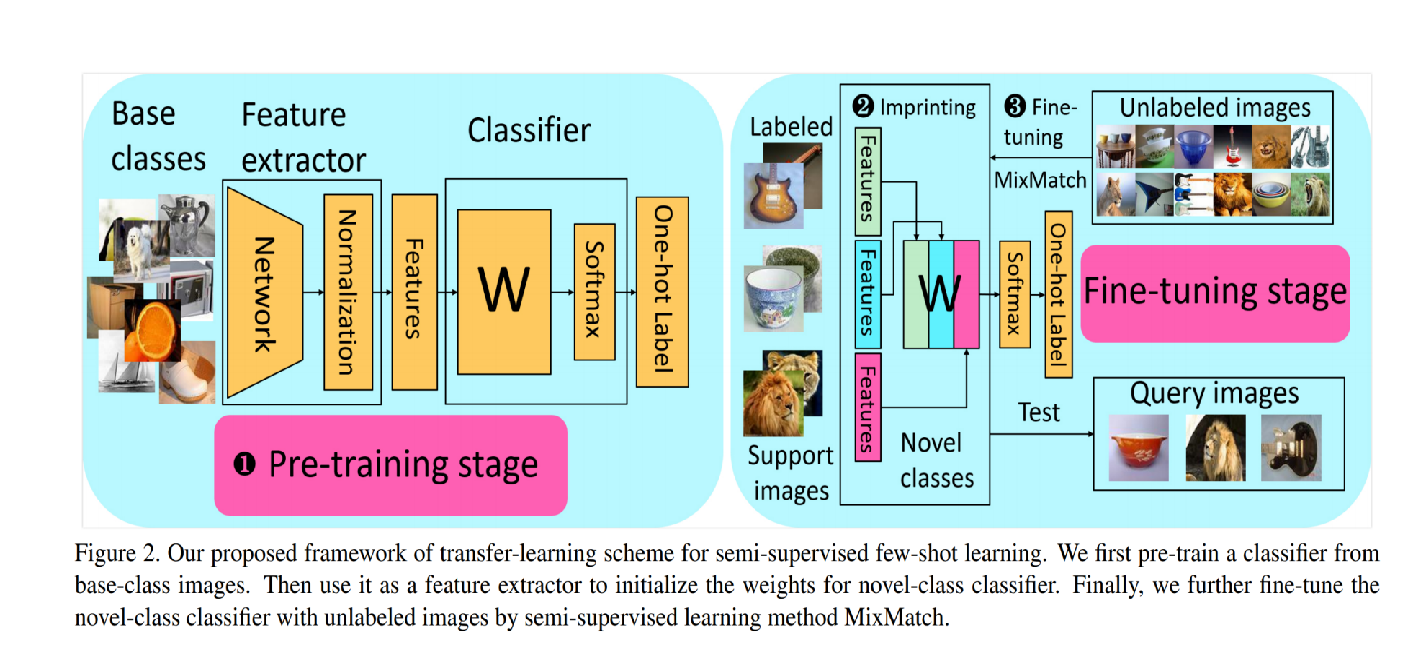
MixMatch的过程大致说一下,就是我有两个数据集一个L一个U,分别是有标签和无标签,W=shuffle(concate(L, U)),接下来使用mixup生成新的L'和U',在新的L'上使用CELoss在新的U'上使用L2loss,主要是因为前者对常数项的变化不敏感(里面有个softmax)。
结果在这里
4. Instance Credibility Inference for Few-Shot Learning
一篇CVPR2020的工作,核心点还是在找一个更好的打pseudo-label的方式,设计了一个ICI模块
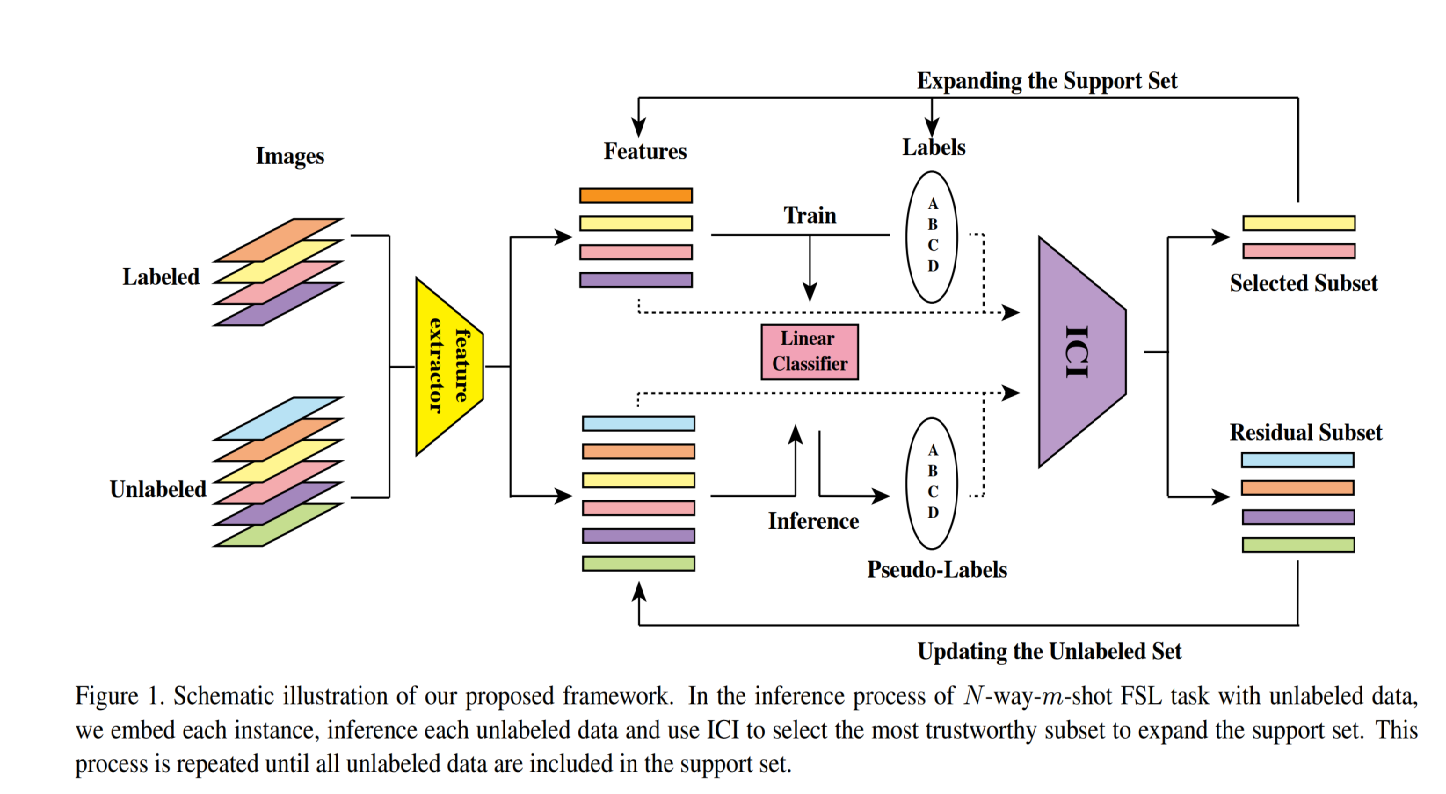
工作的整体流程还是进行一个transfer-learning。后面设计了一个ICI模块来挑选unlabel数据。
这里也放一下算法的流程
以及结果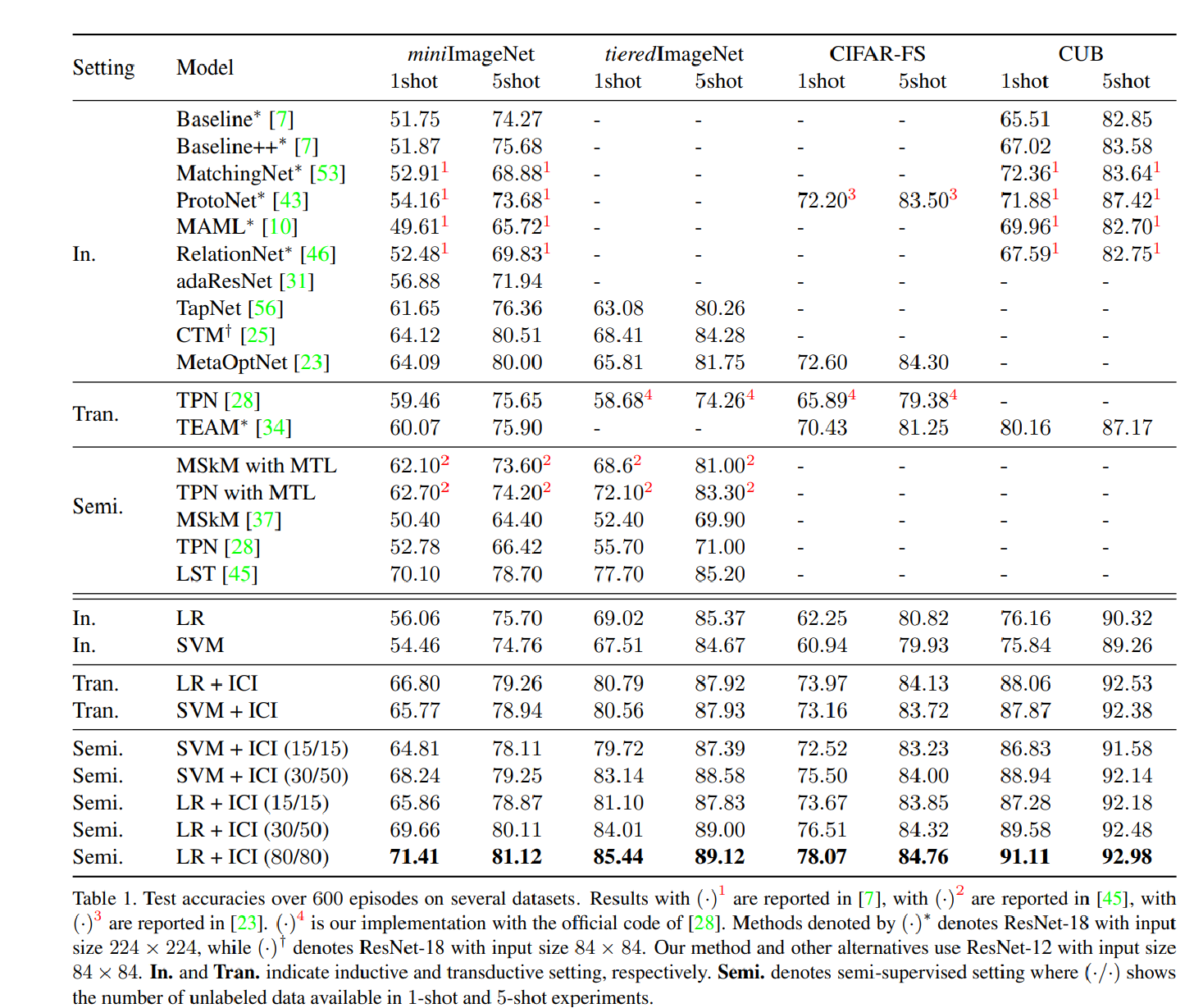
5. Iterative Label Cleaning for Transductive and Semi-Supervised Few-Shot Learning
ICCV2021的工作目前SSFSL的SOTA,也是在探索如何更好的打伪标签,这里利用了图网络,主要流程如下
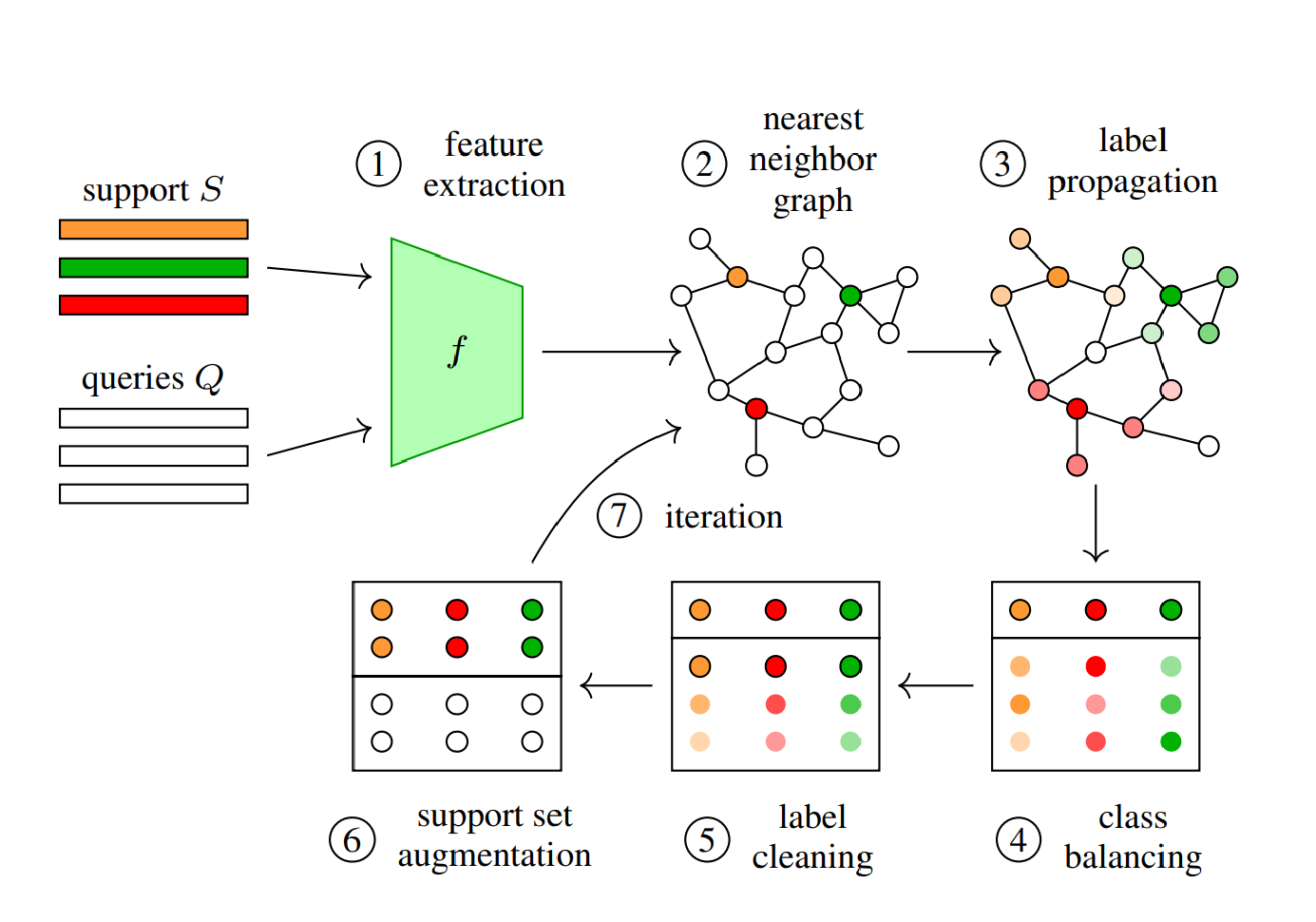
有意思的是吗,这里我觉得没有什么新的创新,特别是在clean label的部分,直接用了现成的O2U网络,在结果比较上也有一些比重就轻的意思在里面。
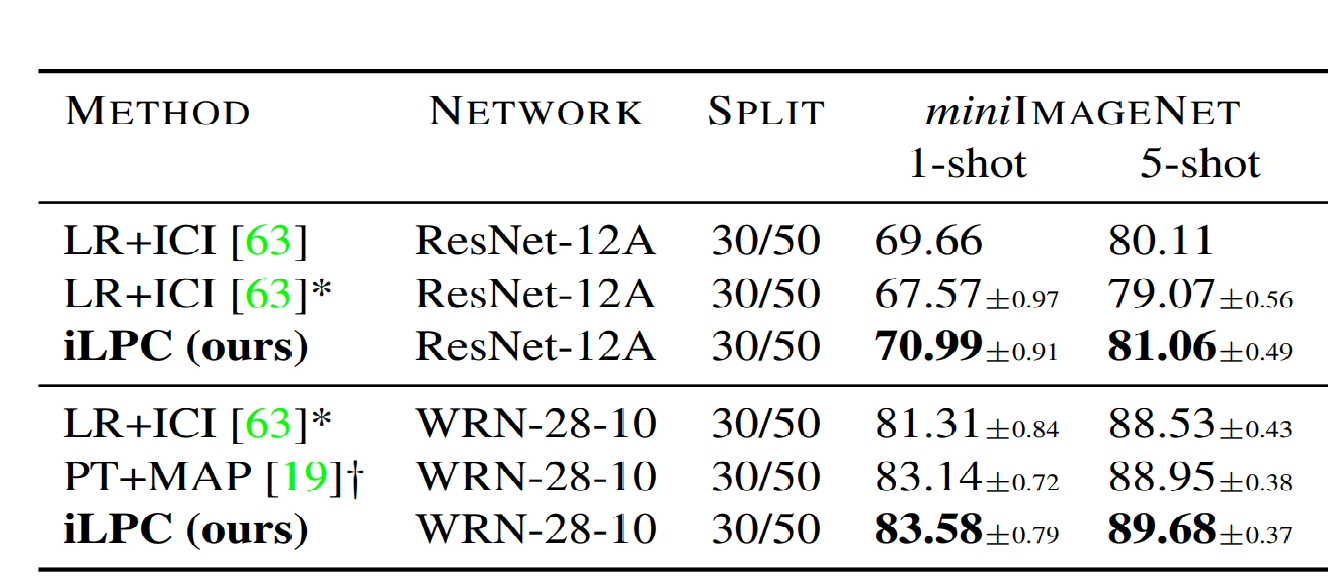
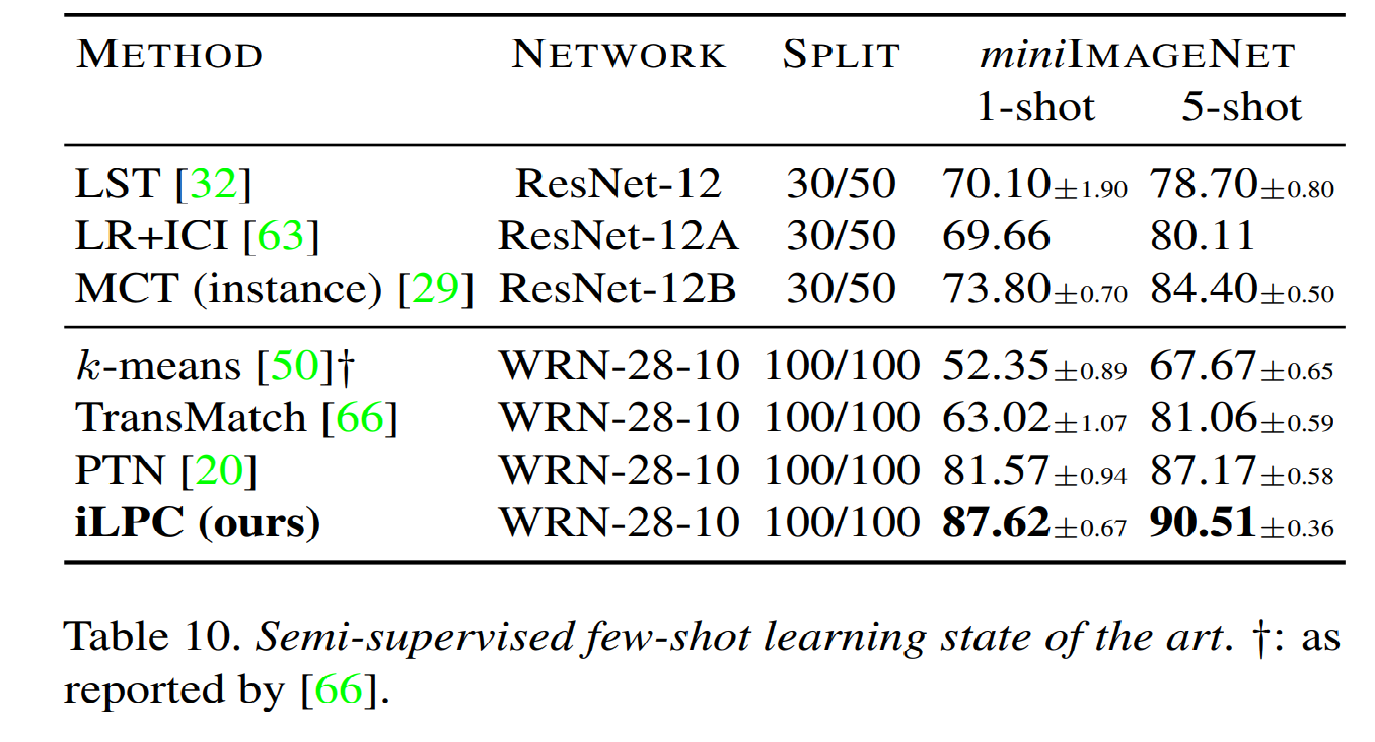
上面两种图看出来小问题了嘛 :)
工作就总结到这。