


Few-Shot Learning
最近看了一些Few-Shot Learning(FSL)的文章,会以这篇为开始,总结和更新,也会把对应文章的链接集中放在这一篇当中。
本篇文章作为这一系列的开端,主要围绕一篇我认为比较好的综述,将FSL问题系统的说明一下。后续文章完成后会将总的目录链接整理在这里
1、Motivation
为什么要进行FSL的研究?我们知道在大规模数据的驱动下,可以完成很多性能很好的任务,比如我们熟知的分类、目标检测以及分割等任务。但是在很多场景下,我们很难收集到足够多的且质量满足需求的标记数据。另一方面,机器学习或者说人工智能的目标就是要让机器有人的智能,人就可以通过只观察少量样本学习到新的知识。所以FSL也是实现通用人工智能目标的过程中必须克服的问题。
2、Definition
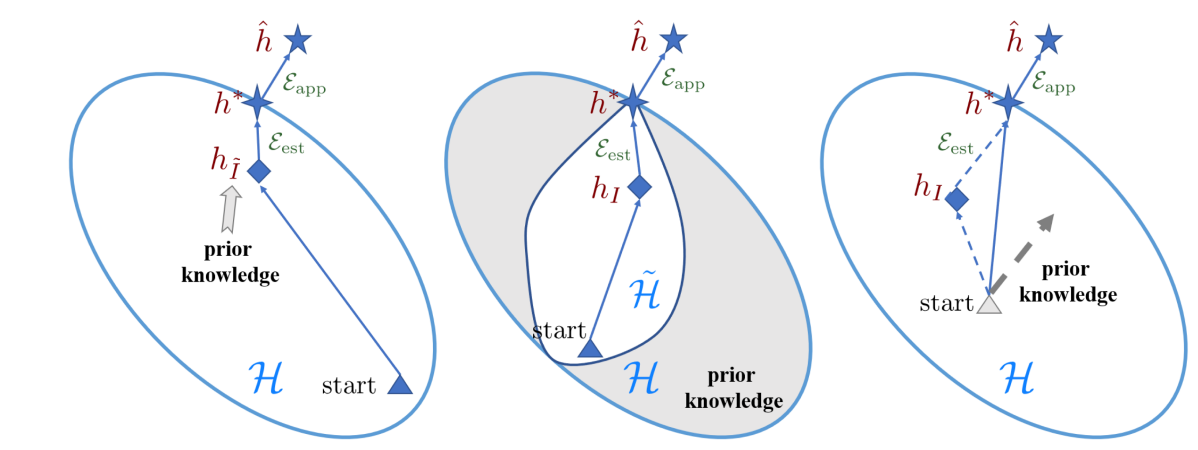
介绍完了FSL问题的动机,那么在这里给出一下定义。直白点的解释就是,我有一些先验知识,在这个基础上,在新的类别上通过很少的样本就可以学的很好。这里的先验知识有很多种,比如说额外的数据或者pre-trained的模型。
这里有一些概念也需要提前说明一下。
在新的类别上,经常会看到这样的说法,5way1shot,这个就代表数据有五个类别,每个类有一张数据。另外会将数据分为support set以及query set,support set中就是有5way1shot的数据,在query set上是对应类别的未标注标签的数据,我们要做的就是对test数据集中的query数据进行分类。
3、Problem
有了2中的定义,那么问题来了,我们很熟悉transfer learning,但是迁移的target domain的数据很少,就会带来很明显的问题就是过拟合,empirical 的误差会不准确。
4、Taxonomy
根据3中提的问题,我们可以将现在的解法进行分类。
我们要解决啥问题呢?咱就是说,过拟合一方面是增加数据,一方面是给model加约束或者让参数更快刚好的找到。
根据以上,将当前的方法分类如下:
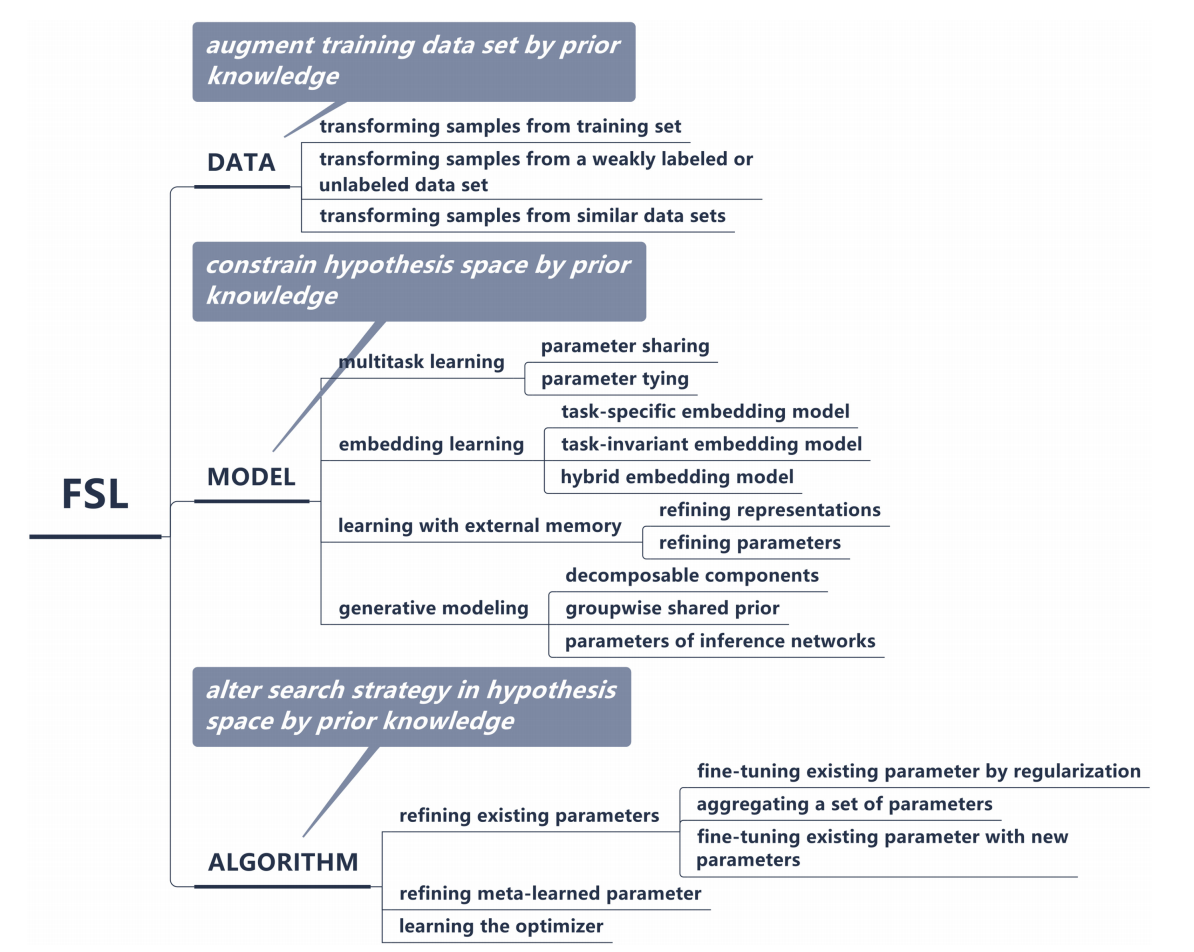
这里简单介绍一下三个类别分别是啥意思。
- DATA:也就是说通过各种手段增强数据;
- MODEL:通过给模型加一些约束,减小搜索空间;
- ALGORITHM:基于先验知识改进搜索策略。
三者比较形象的解释如下:
4.1 Data
说到对于数据的处理,首先会想到的就是我们常用的数据增强,例如随机翻转,剪裁这些。但是这些其实需要我们对于数据进行观察,不能所有的数据上来就这样做。
另外还有一些数据增强策略可以用到额外的数据,比如说有很多unlabelled数据,我们训练一个分类器对这些unlabelled的数据进行分类,把置信度高的数据就给他打上对应的标签,另外也可以通过聚类的方法对这些没标签的数据进行聚类。还可以使用GAN对数据进行生成。
总的来说,数据增强的方式有很多,如何去做还是要看对应的环境情况。例如我就是有很多weakly supervised数据,那就可以用分类器把置信度高的筛选出来。
4.2 Model
模型的方法我觉得对我更有用一些。基于上面分析的问题,在FSL中只要模型的参数足够多就行,也就是说够用就行(但按理说所有的都应该这样吧)。这里主要介绍三种方式。
4.2.1 Multitask Learning
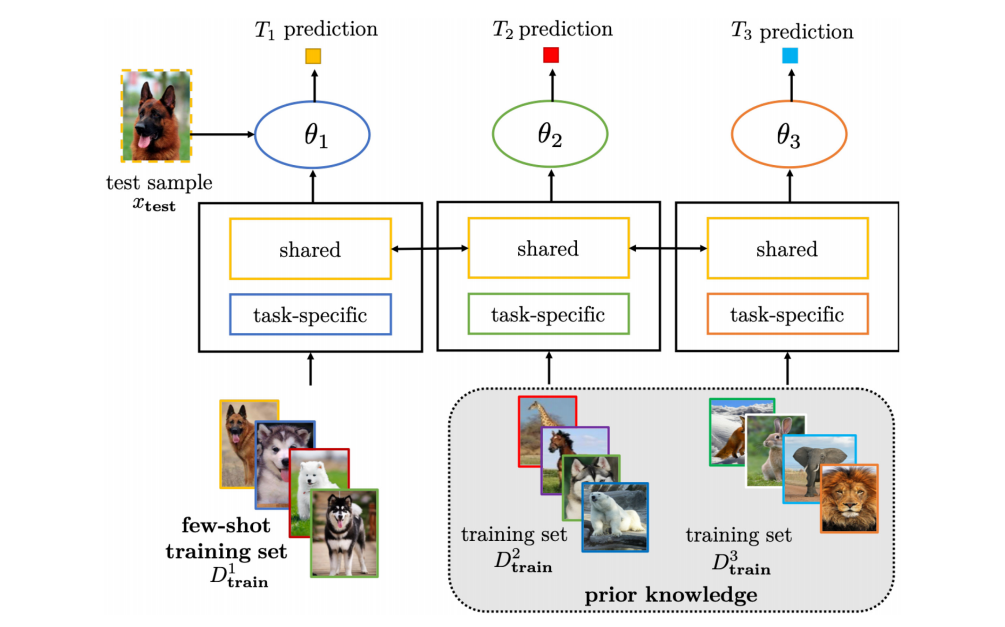
这个多任务学习主要的过程如下图所示。也就是说我在有关的任务上一起训练,这些正常数据规模的任务叫做source task,我FSL的叫做target task。这里的共享参数,可以只有generic的层共享,其余的例如分类头这种东西就根据问题自己定义。
4.2.2 Embedding Learning
这里的叫法,我刚开始也有点不明白,但是论文里解释过后,就很明了。还是基于上面问题的假设,当我把输入数据embedding到中间变量之后,例如encoder处理一下,相当于给H了一些约束。有道理的嗷。
在这部分,终于看到了几个常见的FSL方法,他们都被分类在了这里。
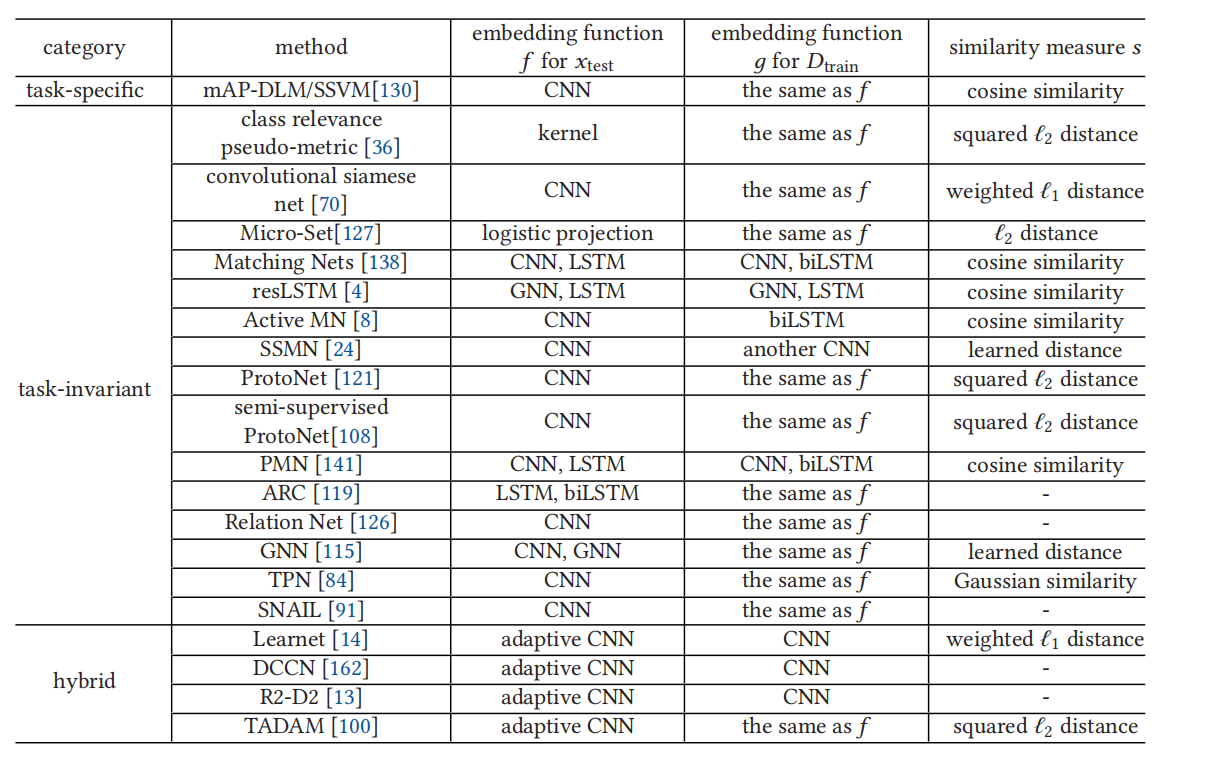
比如里面的Matching Net、ProtoNet、Relation Net、Semi-Supervised ProtoNet以及GNN等,在之后的文章里都会有介绍(看是看了,但论文更新不更新看看有没有时间)。这里的方法主要就是在训练阶段学习一个特征提取器,还会根据test阶段的设置,在训练时构造support以及query,通过特征提取器提出feature map,然后比较query中数据和support中数据的距离,来作最后的判断。主要流程就是如下。
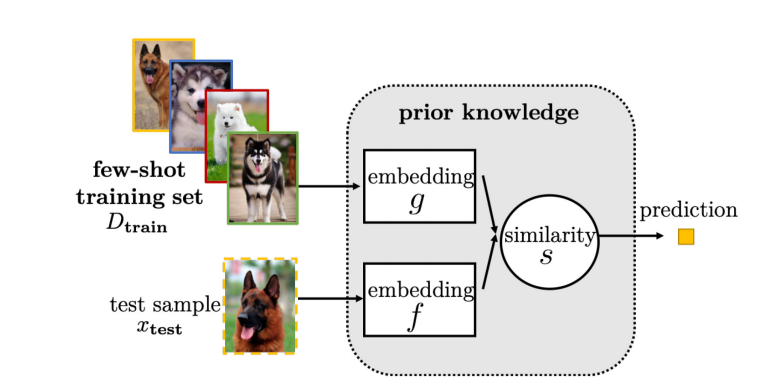
当然还有一些方式,将support中的feature map也作为提取test feature map的输入如下。
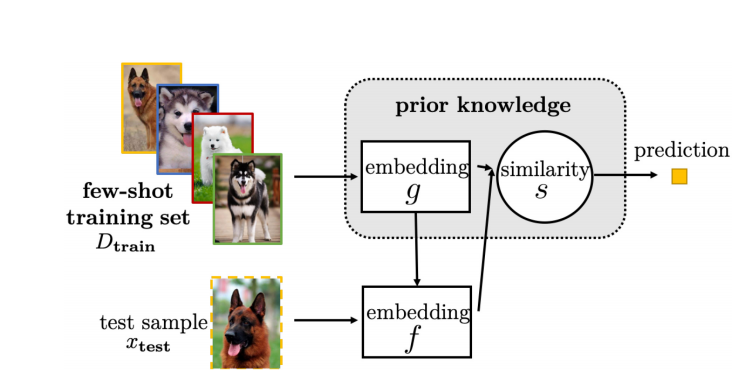
4.2.3 External Memory
这里简要介绍一下,目前看有关这个方面的相关的论文比较少。
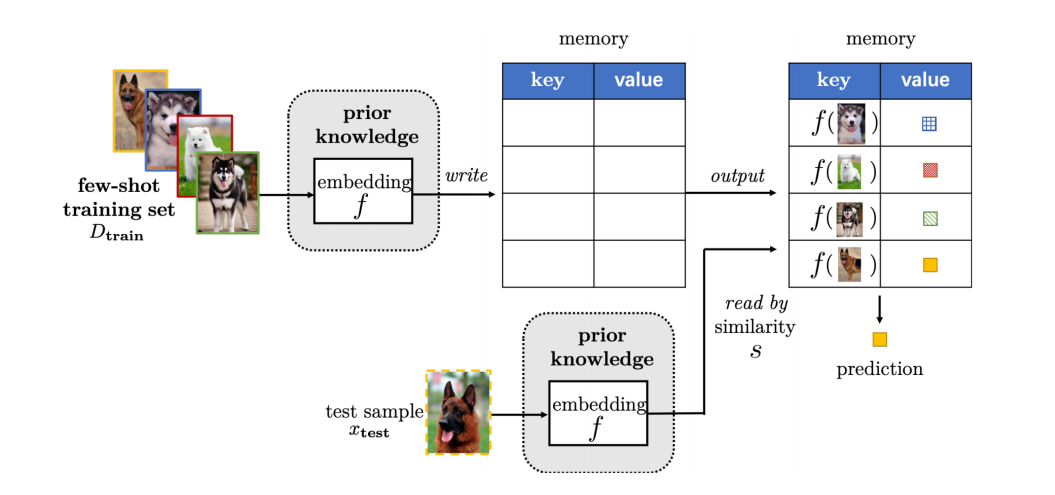
我的理解就是,它是开辟一个memory空间,将support提取的特征(或者说是合格特征提取器的输出)作为key,类别作为value,对test也是这样,所以可以由test的输出在这个memory中进行搜索得出最后的类别,这样一来就大大缩小了搜索空间H的大小。
4.3 Algorithm
这个类别的方法主要使用先验知识改进搜索策略,主要介绍下面的几种方法。
4.3.1 fine-tune existing parameter by regularization
这个我认为就是通过一些方法,让pretrained的模型可以在few-shot上进行微调。例如划分出来validation进行early stopping,对参数进行有选择的更新等方法。
4.3.2 aggregateing a set of parameters
这里就是比如我有一些相关的任务,例如做人脸识别,我没有直接的先验,但是我有识别眼睛的先验,有识别鼻子的先验等。我就可以对这些参数进行聚合。简单的示意图如下。
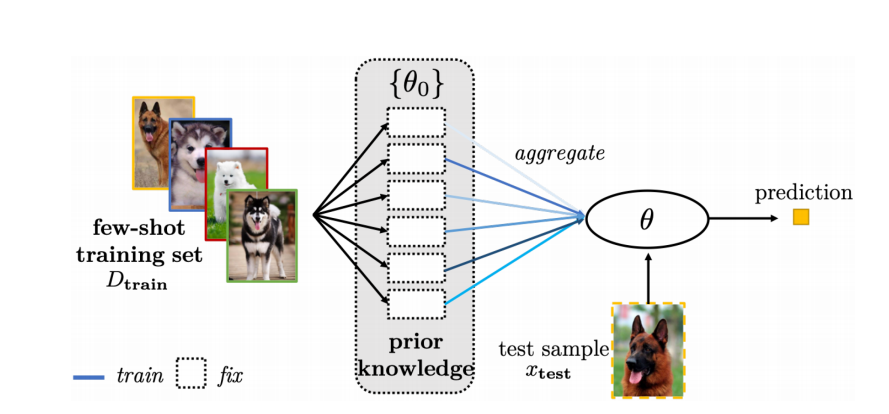
4.3.3 add new parameters
如果我们基于先验得到的参数不够用或者不太适配我们的问题,就可以加入新的参数,让新的参数进行更新,已有的参数进行微调,可以通过采用不同lr的方式实现。
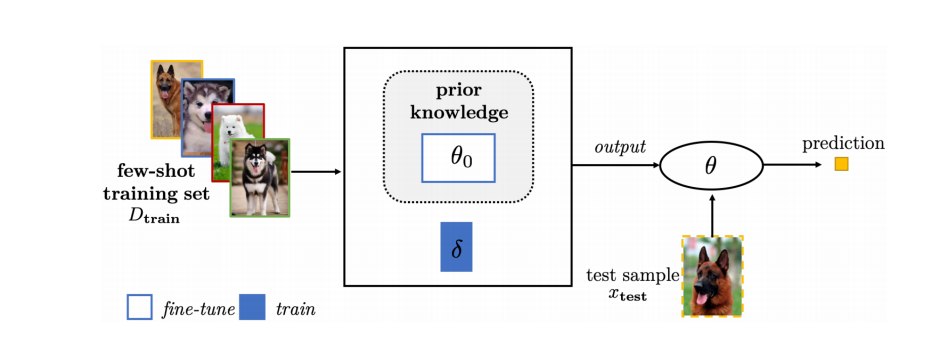
提一句Meta-Learning
光看名字就觉得是一个很高级的概念,比较翻译过来叫"元"学习。首先元学习的目的就是,我先在多个task上进行训练,之后会学到一个generic的知识,我们希望可以用现有的知识来解决新的问题,也就是说让机器“Learn To Learn”,更酷了。因此,其实FSL问题可以通过meta learning的方法进行尝试。