


想系统且细致的看一下LLM及MLLM的工作,之前一直跟到了BLIP2,后面的就了解的不全面了。这一系列的文章会有一个章节进行扫盲,比如这个工作里提到的held-in和held-out之类的。开始开始!

Motivation
NLP里instruct tunning用的很多了
但还没在VLM上做过验证,因为视觉任务和相关信息更加多样,想让一个uni的model,在多样的任务上微调之后,又可以适应多样的任务,且对于一些unseen的任务也可以做得不错,这对finetune的方法泛化性要求高。
InstructBLIP 数据集构建
为了保证数据及任务的多样性,作者构建数据如下图所示。
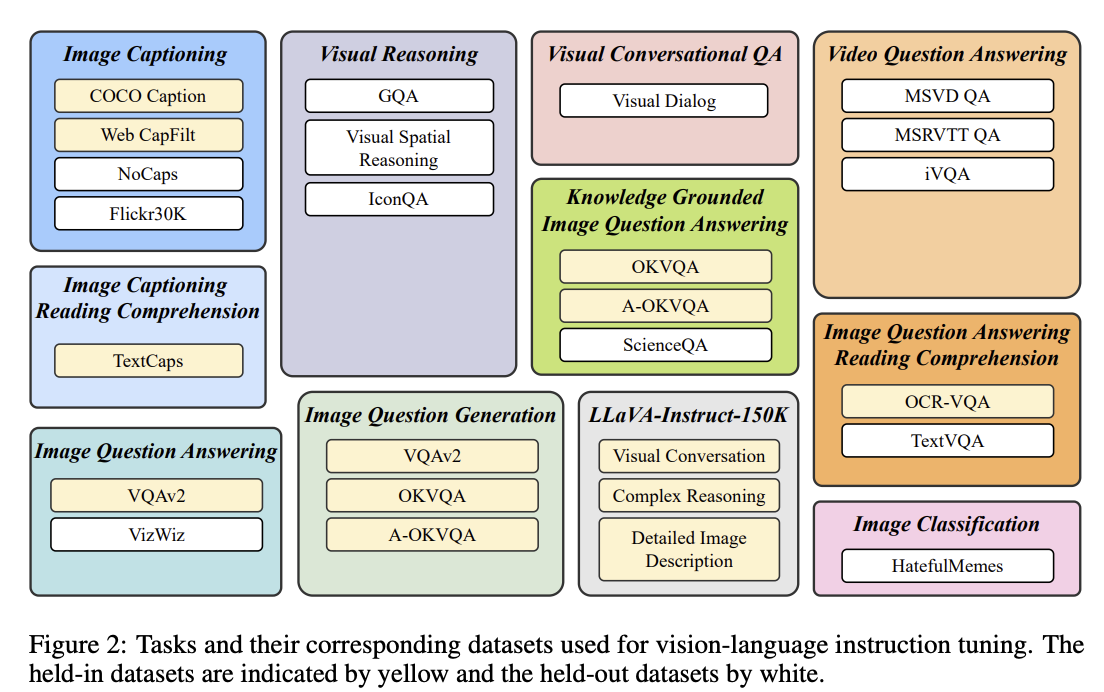
文中选择了26个数据集11中任务,其中白色的是held-out的数据,黄色的是held-in。
对于每个任务,作者构造10-15个instruct的templates,如下图所示:

这里需要暂停一下,之前其实自己也有想过用多模态的数据进行微调,比如把image的embedding和text放在一起,但当时下意识觉得这样行不通,看来还是了解的太少。
值得注意的是,因为数据集和任务都很多,为了防止模型有过拟合的问题,作者设计了采样策略,其实很简单,多的少采一些,少的多采一些。
InstructBLIP训练
首先回顾一下BLIP2的模型结构和训练过程,模型结构如下:
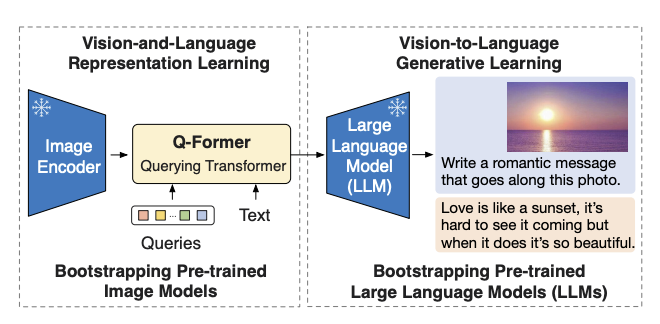
训练分为两阶段:
- 没有LLM,带上freezed imgae encoder,预训练初始化Q-Former。
- 带上LLM,微调Q-Former
InstructBLIP基于BLIP2,方法结构如下:
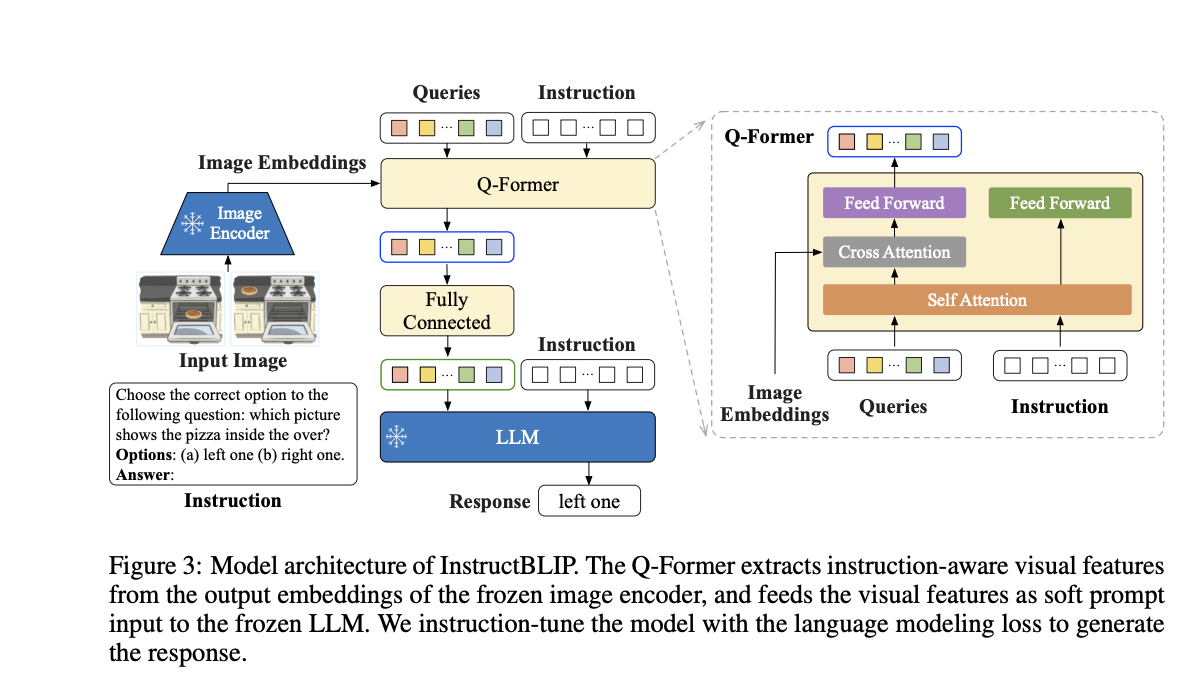
其实和BLIP的比较一致,重点看一下Q-Former的改变。通过一个self-atten让learnable queries和instruction先交互一下,后面再和image的feature做cross-atten,这样我认为会多出来和任务相关的信息。其他的训练策略其实就和BLIP2一致了。
定量/定性实验结果
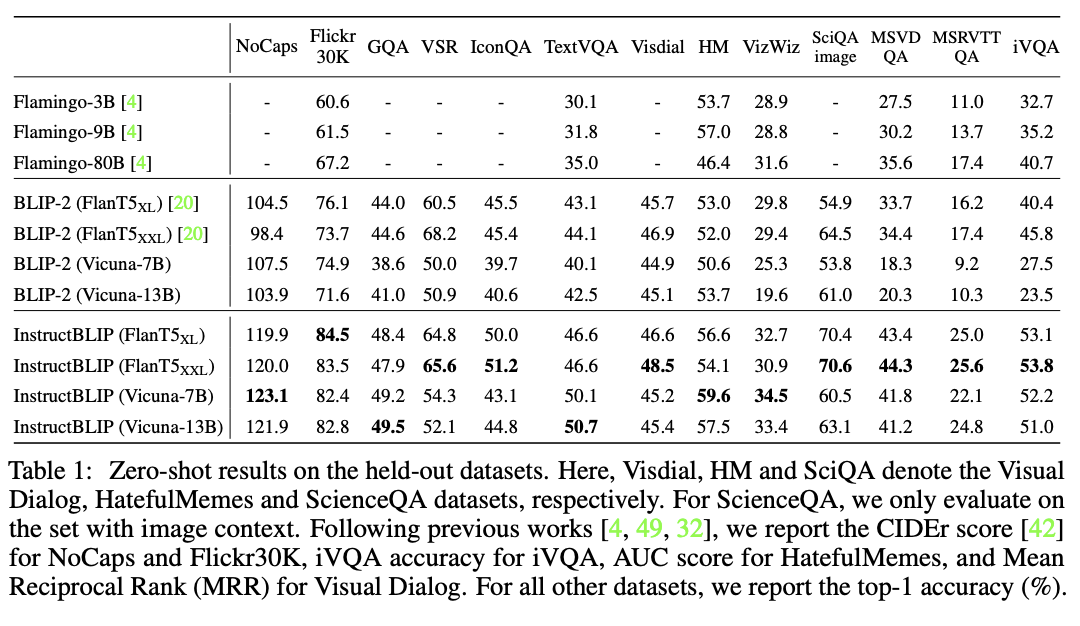
结果上确实比BLIP2好上不少。
再看定性结果:

从定性结果上看,回答更加简洁了,也就是和任务更相关。

从这个例子中,虽然变得“不简洁”了,但这个问题本身就是要发现不正常的地方,给一个更加详细的描述和问题更贴切,因此效果应该也是更好了一些。
扫盲
held-in:也就是在训练的时候被看到的数据
held-out:与上文相反就是训练时没有被看到的数据