


DDP稍微深入的理解
在之前写代码的过程中,最常用的方式还是DP,因为用起来实在是太方便了,一句话就能解决问题,但是后来看到还有DDP的方式,在使用过程中遇到了不少问题也没解决,这次就集中学习一下
1
为什么使用DDP而不用DP
DP的使用虽然方便,但自身存在一些缺陷,比如负载均衡较差、效率不高以及和模型并行不兼容等。官方目前也是推荐多使用DDP,DDP。
DDP介绍及举例
在开始前明确一些概念
- Node:节点,可以理解为主机
- Deivce: 可以理解为一张GPU
- Process: 可以理解为一个在跑的py程序
- Threading: 一个process有很多线程,共享资源
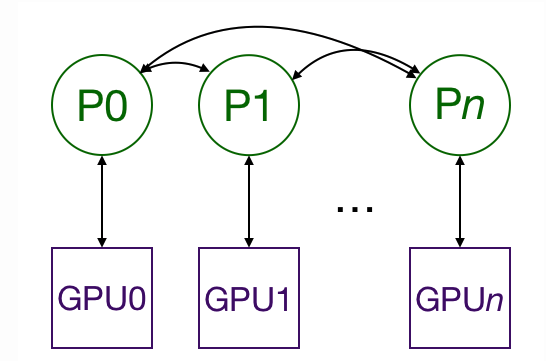
DDP作为一种数据并行的方式,即单机/多机 多卡运行,如上图所示,每张卡上都会有一个进程,有一个模型,处理对应的数据,每张卡训练自己那部分数据,在更新的时候也是,即每张卡上的模型是由这张卡上的process独立控制的。
举个例子,A个模型,N*M个数据,N张卡,那么每张卡就分得M个数据,为了更简洁的解释,假设每张卡一个进程,那么每张卡都独立训练这个模型,在做更新的时候,N张卡loss得平均,更新所有模型,这样的话,时间也就是计算M个数据的时间。
使用举例
- 每张卡有一个进程,所有的进程可以理解为要统一管理,所以要形成一个进程组,初始化一个process_groups
dist.init_process_group("nccl", init_method='env://', rank=global_rank, world_size=world_size, timeout=timedelta(seconds=5))
这里重点说几个参数,rank和word_size。
首先rank分为global和local,前者就是把所有的卡上的进程进行排序后的标号,后者是在每一个卡上的进程排序的标号。
word_size代表进程数量,一般计算方式为nprocess_per_node*node_num
这里的ncll以及init_method都是为了进程间的通信,用gpu的话就是ncll,用cpu的话是gtoo
- 写训练代码
这里的训练代码其实和普通的没有太大区别,有一点需要注意的是,要给进程分配每张卡的进程号即local_rank
def main_worker(gpu, ngpus_per_node, world_size, train_bs, valid_bs):
dist.init_process_group(backend='nccl', init_method='', world_size=world_size, rank=gpu)
torch.cuda.set_device(gpu)
device = torch.device(CFG['device'])
model=net
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu], find_unused_parameters=False)
- 启动多进程训练
mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, world_size, train_bs, valid_bs))
- 存取模型
这个是我在第一次使用过程中遇到的问题,因为有n个进程独立进行的话,就会保存n个模型,显然是不科学的,肯定有一种方式可以进行控制,这次就发现了。
因为每次更新后的模型都是相同的,因为我们只需要保存一个进程的模型即可,可以加一个判断如下。
if global_rank == 0:
'''
只在Process0保存模型
'''
torch.save(model.state_dict(), CHECKPOINT_PATH)
但是有很多进程,为了避免这个还没保存,另一个都已经开始读了,就加一个barrier让所有进程等一下。
dist.barrier()
另外,在读取的时候也有些要注意的地方。我们要用map_location给一个指定的local_rank,否则的话pytorch默认先读到CPU再将参数完全复制到保存前的设备上。
map_location = torch.device(f'cuda:{rank}')
model.load_state_dict(
torch.load(__, map_location=map_location))
以上就是这次对DDP稍微深入的学习,这些内容已经完全能满足训练的需要了。