


Paint by Example: Exemplar-based Image Editing with Diffusion Models
生成模型的效果总是很惊艳,但目前比较多的还是基于text prompt的图像生成。这段时间想到有没有方法对选中区域直接用给定的图进行inpaint,发现CVPR23上有两篇文章正好在做这件事,一篇是阿里的AnyDoor,另一片就是今天要介绍的Paint by Example。
1、Motivation
- text-gueded image edit做的比较多了,本文提出一个基于一个固定例子的image edit还比较少
- “一图胜千言”,用图像作为指导的话要比文本在特征上更丰富
给出一个形象的例子展示一下论文要做的事情

如果不从技术角度出发,我们来想一下会有哪些难题
2、Challenges
- 随便给一张example图像,模型要理解其中的形状、纹理甚至是语义,但又不会过分关注背景的信息;
- 对抠图区域进行转换,能自己适应,且边界转换平滑自然。
3、Methods
能想到最简单的方式肯定就是直接把example放在这里,在让它适应周围的情况,本文中做出来的效果如下:

发现生成的图像和周围环境并不能很好的适应,文中思考是因为模型过度学习了一个映射函数,阻碍了模型自己学会理解图像之间的拼接链接,导致泛化失败。
作者根据这样的问题进行了改进。
先看一下方法训练的流程
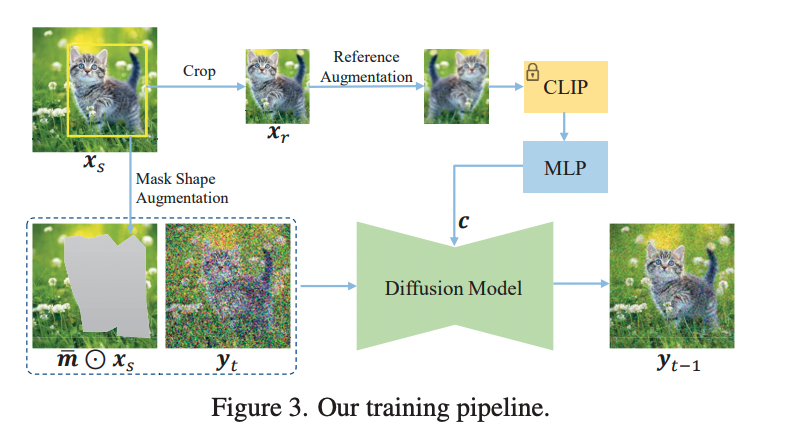
3.1 Information Bottleneck
text-guided让模型学习语义,但是相对来说会难,因为信息少。image-guided让模型更容易理解上下文信息。作者通过压缩image的信息,给模型上难度,讲224224的图变成了10241的向量表示。接着用了一个更牛的well-trained diffusion model。
3.2 Strong Augmentation
通过这个方式,大大提高方法的鲁棒性
3.3 Mask Shape Augmentation
基于bbox生成任意形状的mask,对box中的边进行贝塞尔曲线进行拟合,并使其在原有坐标上进行小像素的便宜,减轻归纳偏置,提升泛化性。
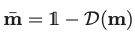
3.4 Control the similarity degree
为了控制编辑区域和参考图像的相似程度,作者这里手机了classifier-free的策略,结合了先验及后验的约束。
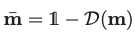
其中s越大表示对example的依赖更大。