


Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models
机器人领域的VLA逐渐火热,但是在快速发展的过程中还有很多没解决的问题,以及经过验证的结论,字节这篇类似empirical study的工作对很多问题进行了讨论。
1、Overview
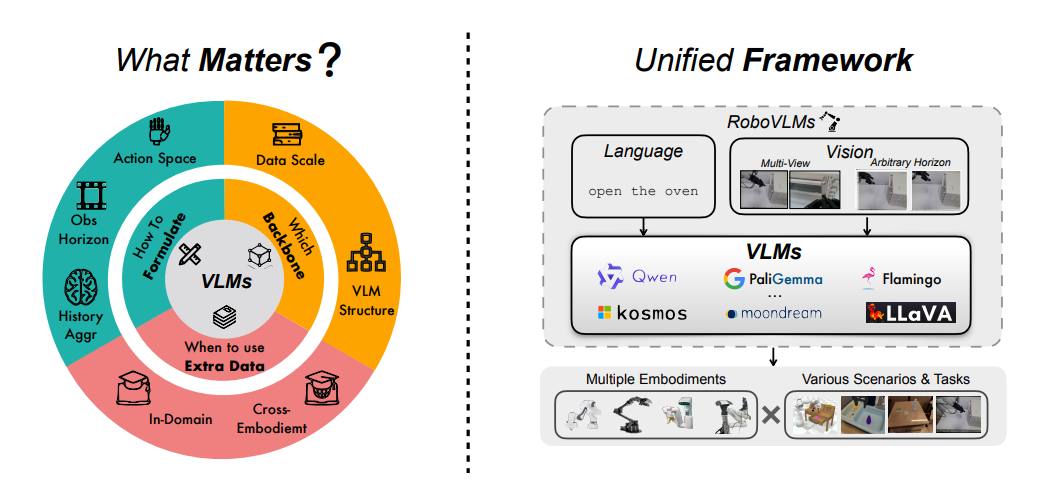 随着具身智能的发展,VLA这样端到端的模型在有限的数据上展现了很好的效果。但在发展的过程中,有很多问题没搞清楚,例如在构建这样一个大的系统时,数据、模型以及策略都会产生影响。如上图所示,在数据侧、方法设计侧以及训练的方式方法上都会有很多问题,每个问题对效果会有怎样的影响,都是亟需探讨的。
随着具身智能的发展,VLA这样端到端的模型在有限的数据上展现了很好的效果。但在发展的过程中,有很多问题没搞清楚,例如在构建这样一个大的系统时,数据、模型以及策略都会产生影响。如上图所示,在数据侧、方法设计侧以及训练的方式方法上都会有很多问题,每个问题对效果会有怎样的影响,都是亟需探讨的。
本文首先对现在的问题进行总结并逐一验证给出现象和结论,同时也提出了一个公平且完整的验证框架,工作量大且扎实,值得学习。
2、Problems
文章提出了很多问题,列举如下:
- 为什么要用VLA?
- VLA在real-word中如何表现得更好?
- 什么样的backbone构造VLA表现更好?
- 什么样的范式构造VLA表现更好?
- 对于cross-embodiment的数据集,什么时候用最好?怎么用最好?

除此之外,为了后面讨论方便,这里还对目前VLA方法先进行了一个分类,也是对这个领域比较大的贡献。而且,对于像我这样之前零零散散看VLA的人来说,也是很大的帮助。
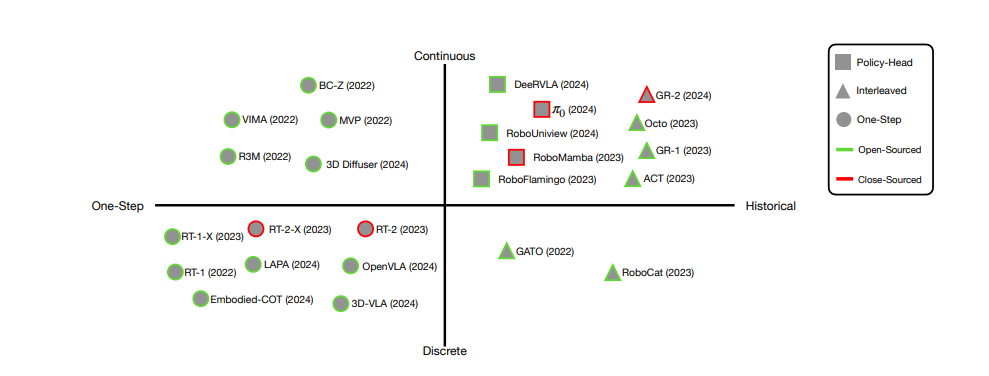
2.1 Why do we prefer VLAs?
提到VLA就离不开VLM,VLM已经被验证可以在open-vocabulary设定下有很好的泛化性,得益于在VL训练的过程中,有了比较general的语义信息在里面。
因此,我的理解里VLA继承了VLM这一优势,pretrain后的模型本身就具备更好的泛化性,所以VLA是机器人下游任务提高泛化性更好的选择。
在回到这篇文章,放个结果吧
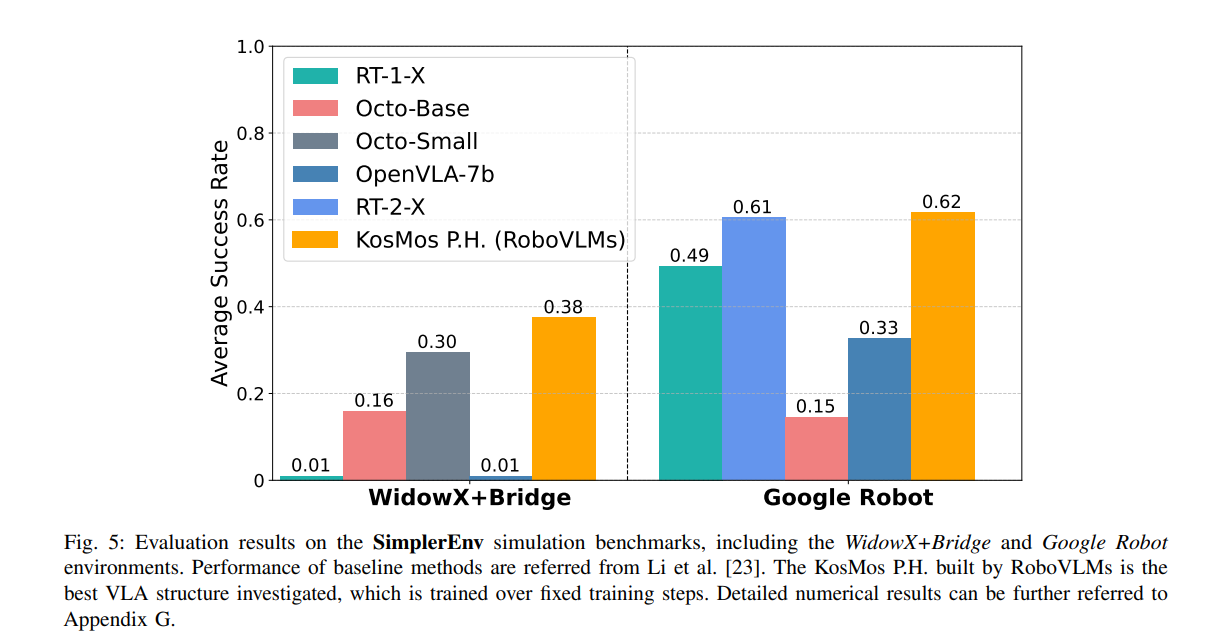
2.2 How do VLAs perform in real-world scenarios?
按照文章的顺序,这个问题放在这里我觉得不太合理。文章中给的结论就是,它提出的模型这样设计最好,那为什么这样设计呢,其实是后续几个问题找到的答案。
那我们这里就直接上结论,连续动作控价+分开的policy head+post-train+kosmos做backbone=最好
2.3 What is the best-performing VLA structure?
这也是一个值得探索的问题,连续的好还是离散的好?输入要不要考虑in-context信息或者历史信息?
用直觉判断其实也有个结果,但这篇文章在实验上做了一个验证,例如连续的对长程和精细操作有益,历史信息很重要等。
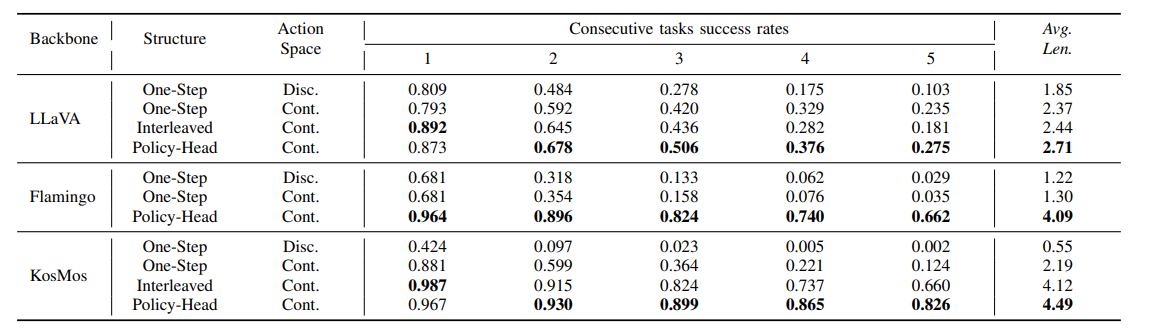
上方表格基于不同的backbone,对连续/离散的动作空间进行了比较,同时对one-step、interleaved以及policy head做了实验。
这里可能会有个疑问了,one-step interleaved以及policy head都是什么东西,这里贴图看的比较直观。
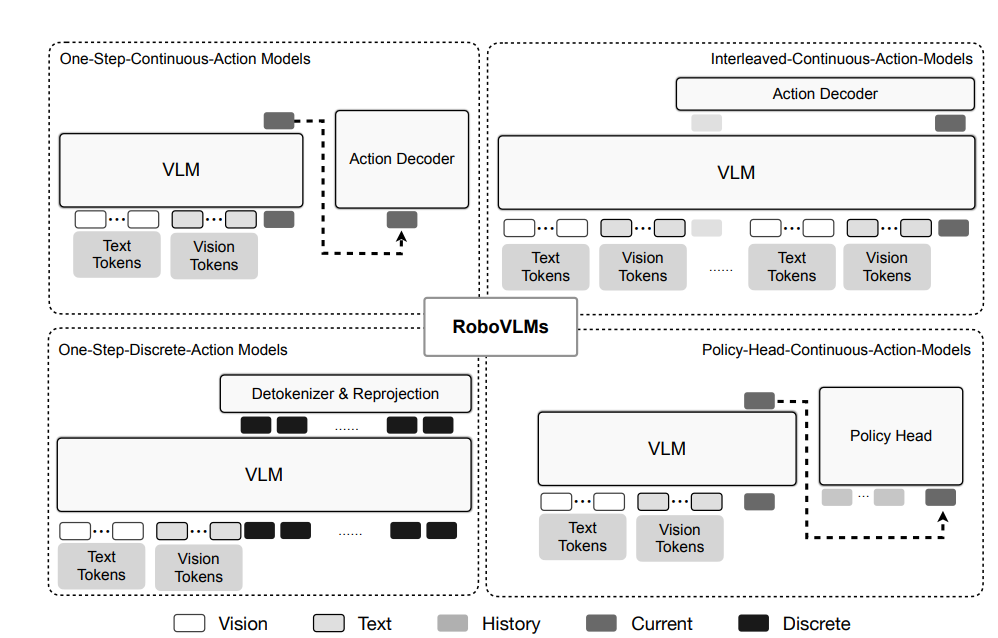
总结一下,我的理解哈。首先连续和离散区别的标志就是,连续的都通过一个model做fusion得到一个learnable vctor再做后续的decoder,但离散的是直出sequence。interleaved和policy head有点像,但做时间维度的fusion位置不一样,前者是先fusion,后者是在head部分再fusion。这个有点像在多模态里,blip那一系列讨论early fusion的。
2.4 How do large-scale cross-embodiment datasets contribute to VLAs?
最后这个问题是我最关心的,因为想让VLA能scale up,或者让它像cv或者nlp一样能发展的更迅速,最关键的还是数据。前一段出来了很多大数据,但基本都是cross-embodiment的,也就是里面的机器人本体不尽相同,在这样的情况下这些数据集该怎么用,有什么用就是需要探索的问题了。
也是直接上结论:
- in-domain的数据比大规模cross-embodiment的数据更重要;
- 在使用的过程中,相比于pretrain,像π0一样做posttrain更有效;
- 高质量的预训练VLM,有很大的帮助。
这里提一下最后一点,这个也就是我们在2.2中选KOSMOS做backbone的原因,就是因为它的预训练比较干净效果比较好,对下游VLA的助力也比较强。
3、Platform Settings

这个我们就不过多展开了。
4、Conclusion
总的来说这是一个很好的工作,除了给出一些结论及对应的实验验证外,还整理了一套代码框架,让大家可以更加快速的推进这个领域的工作,值得一读