

Deep Spatial-Semantic Attention for Fine-Grained Sketch-Based Image Retrieval
CVPR2017,就sketch me that shoe改的
刚发现论文作者之一的宋老师实验室就叫SketchX,牛啊
最近又把这篇文章看了一下,做一些更新
1、Overview
这篇文章是基于sketch me that shoe上进行的。
主要工作如下:
- 为了让模型更加关注到细粒度的特征,加入了soft attention;
- 因为两个模态经过映射之后其实存在不对齐的特征,所以加connect,最后换loss里的energy function;
- 又加connect来fuse coarse 和 fine 的粒度特征。
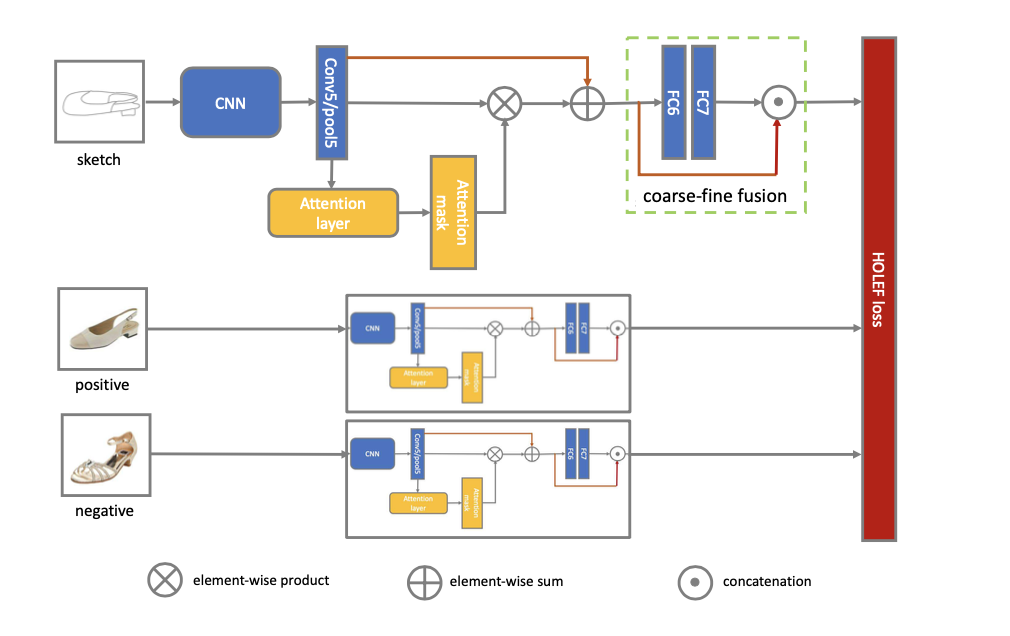
2、Methodology
先放网络结构图
整个流程也很简单,就还是在triplet的基础上进行改进的,具体的接下来介绍。
2.1 Attention
这里加入attention是因为作者认为,之前的网络并没有太多关注到细粒度的特征,这里的的attention实现也很简单,就是两个1x1conv的结合。
2.2 shortcut connection
这里的连接就是resnet里的一样,有两个地方用了。
第一个是在attention模块,是因为,作者认为因为提取出来的vector是不对齐的,因此直接做attention map就是错的(是不是有点绝对了),因此用shortcut将没有attention的vector加了过来。
另外一个地方就是后面要经过fc的时候,经过两个fc,得到了attention map就🈚️了,所以又加了一个shortcut直接连到后面的输出部分。
这里并不是attention无了,我理解的attention是一个很敏感的东西,经过任何计算的处理都会损害他的特征表示,而且全连接层也是一个计算性很强的东西,所以可以理解。
2.3 HOLEF Loss
这里的triplet loss其实和之前的思路还是一样,就是将之前的欧式距离换成了高阶的方式
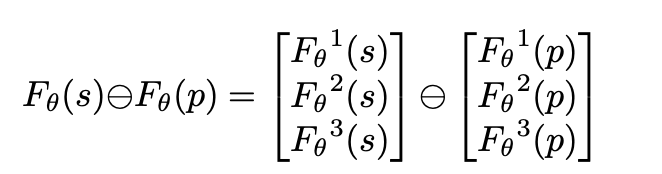
像这样,结果
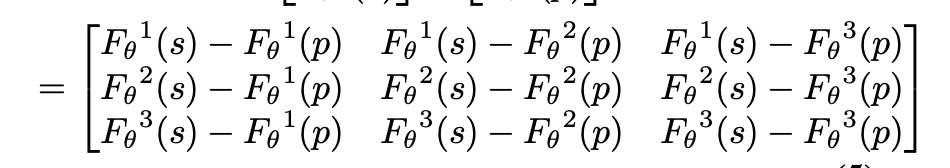
可以看出,多了很多重复的项,我的理解就是多了更多的冗余,可以cover掉一些feature没对齐的问题。在接下来也会对这个loss加一个权重继续进行计算。
为什么要换呢?因为是一个跨模态的任务,因此feature map不对齐,欧氏距离只会关注对应像素点的关系,忽略了无关的像素点,在这种情况下会损失一些信息。
3、Insights
这个文章中加了注意力等,肯定要比没注意力的效果好吧,but,but,but,在场景的FGSBIR问题当中,这个方法没有sketch me that shoe的效果好。但是这俩网络一直都是后来很多论文的baseline。
在消融实验中,我们可以看到其实HOLEF的这个改进提升点很有限,它确实有道理,但没有从那么有深度的方面有一些改进。当时cross domain的研究还没有很多,这篇也是个不错的尝试了。