


Doodle to Search: Practical Zero-Shot Sketch-based Image Retrieval
封面的烟火气(废话开篇)
最近看一个cvpr oral的相关论文,还挺强的,方法和应用场景都很好,就是涉及到强化学习有一些地方还没完全理解,这周要了解个差不多,周末把代码跑一下,准备做实验了。
1、Overview
先总结一下这篇文章吧,后面再慢慢介绍。本篇文章是CVPR2019的工作,涉及到zero-shot,什么是zero-shot,经常会看到one-shot和zero-shot,从字面上就能看出来,one是这个类很少数据一张,zero就是这个类上一个数据也没有,也就是在seen的类上训练,在unseen的类上inference。
本篇文章提出zero-shot上的FGSBIR问题,我认为还是想之后解决有关数据集很少的问题。虽然是zero-shot,但是它里面的方法对普通的问题也很有实用性(我认为)。
在前人的基础上做的改进主要是:
- 增加domain loss进一步缩小domain之间的差距;
- 增加semantic loss学习更多的语意信息;
- 使用的这个GRL我第一次看到很新颖。
2、Methodology
首先看一下整个模型的结构吧。
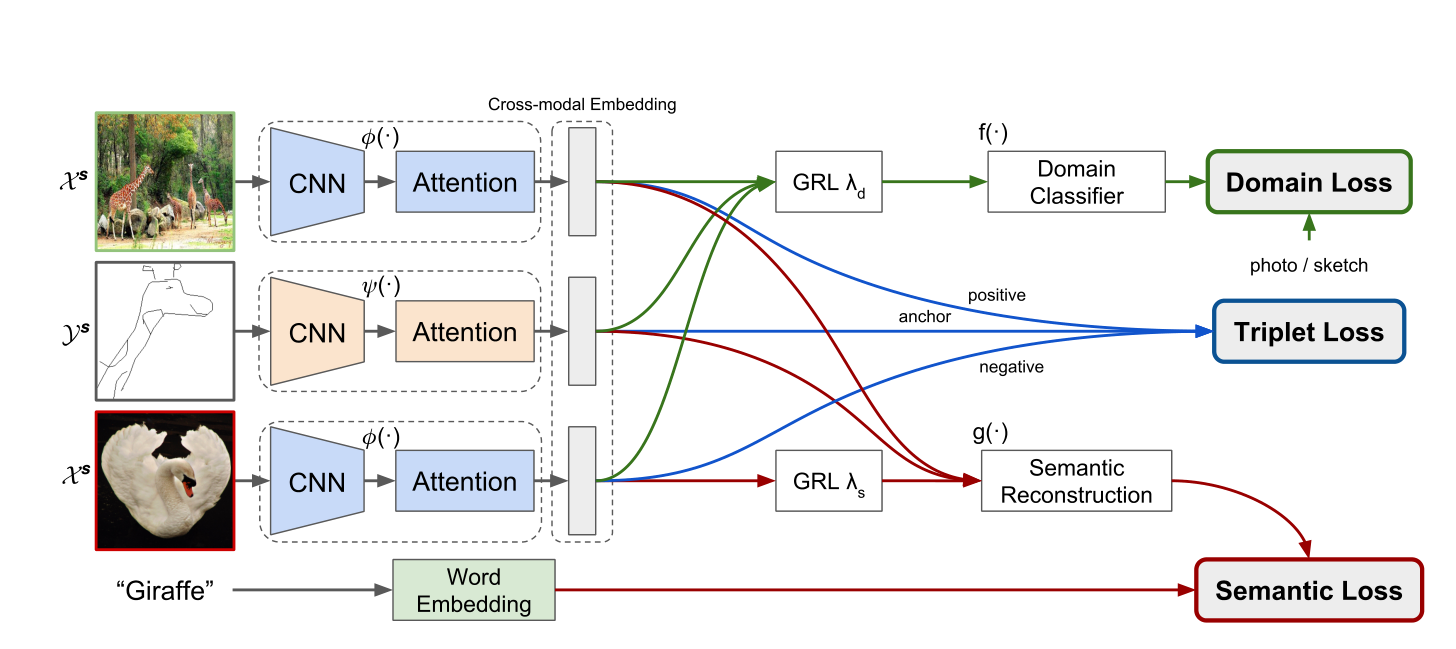
这个结构有没有亿点眼熟呢,前面还是sketch me that shoe中的triplet net,后面也是对应的loss,就是在这个基础上加入了新的模块,下面详细分析一下。
2.1 feature extract
这标题吧,我就乱起一个,代表前面这个提取特征的部分。在sketch me that shoe中,就是三个分支的孪生CNN来提特征,但是为了更好的关注到fine-grained的特征,这里加入soft attention。
之后通过几个FC层,将特征映射到需要的维度上面去就结束了。
2.2 Triplet loss
这几天一直在看相关文章,每次都会看一遍这个loss的计算方法,这里也再说一次吧。由于我们的输入是一个三元组,postive,negative和sketch。因此我们就是要让postive和sketch的距离尽可能的相近,让negative和sketch的距离尽可能的远,很简单的思路对吧,这里的距离是用的还是欧式距离。另外这个三元组损失里加了一个margin,我认为作用是让正负例在特征空间上分布不能那么集中。
2.3 domain loss
2.2中的方法虽然也可以一定程度上对dual domain上的向量进行比较,是一个缓解gap的操作,但是作者认为,没有explicitly的解决这个问题,于是呢提出了域自适应的损失函数。
首先我们要明白在前面Encoder部分,学习的目标是学习到domain无关的特征,也就是说从Image和Sketch学来的两个特征要尽可能对齐,没有差别。
明白了这个之后,再看看什么是GRL,叫梯度反向层,很简洁,forward的时候什么也不做,backward的时候会乘上一个负常数。
为什么要这样做?现在开始介绍一下。真的妙。
后面的Domain Classifier是一个MLP实现的二分类,我们知道分类任务的目标就是尽可能可以分开两个目标,也就是说优化目标是让两个映射后的特征分的更开,这就和前面的encoder的任务存在矛盾的地方了,这时候只要加一个GRL就可以很好的让前后两个任务优化方向统一。这部分的损失使用的是二值的CELoss,如下。
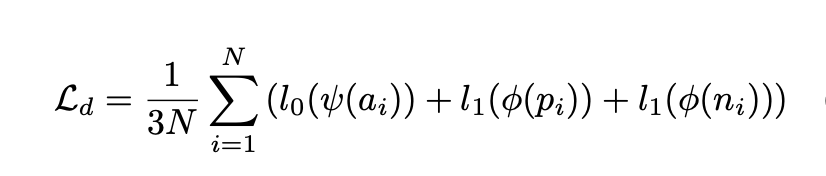
2.4 semantic loss
这部分是为了让Encoder可以更好的从语义上区分正负样本,具体做法就是通过将GT embedding之后做余弦距离计算。设计思路和上面的domain loss相似,但可以发现,只有negative的样本进行了GRL,为啥呢?因为这里的优化目标是余弦距离减小,前面两个输入本来就是GT对应的样本,优化目标相同,只有后面的是相反。
最后的loss是三个loss通过系数的加权。
3、Results
实验结果表示,在自己的sketch数据集上要好于当时的zero-shot方法。

但第一行没有完整的结果,论文中介绍到是那个工作没有具体的实现。
4、Insights
消融实验结果可以看一下。
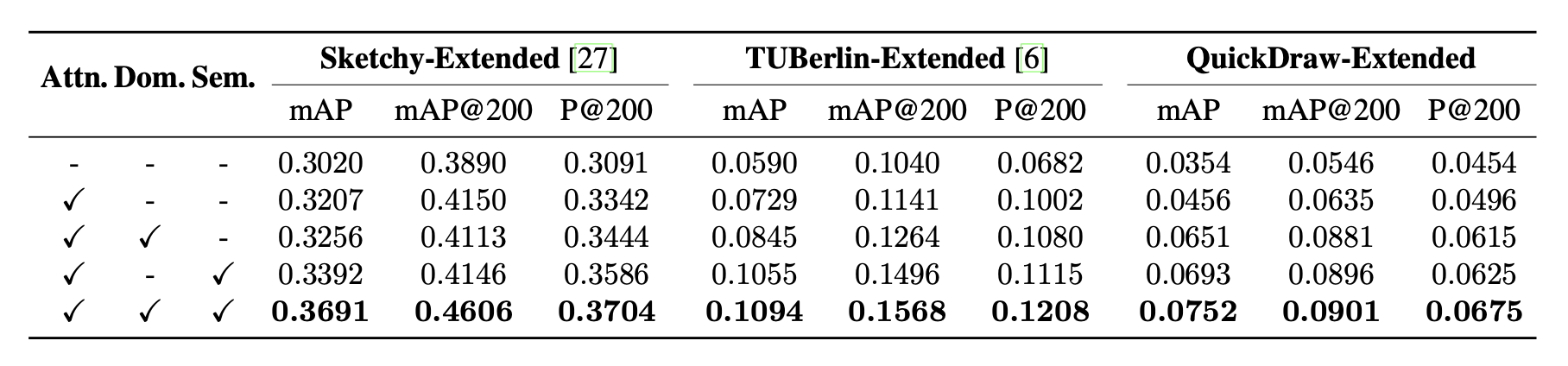
主要我关注了一下domain loss的影响。可以发现在第一个sketchy上的提升结果并不是很明显,但是在后面两个还挺好。这为啥,贴一下这三个数据集的数据。

可以看出第一个它纹理其实相比之下更丰富,后两者纹理很少,线条也不大行。因此domain提升的效果好一点。
另外这个semantic loss其实泛化性还挺好,我分析一方面这是个zs问题,加了语义信息效果会好;另一方面还是因为加了语义信息,学到的更丰富了,在semantic loss部分确实可以拉大正负样本的分布距离。
文章中所有截图都来自该文章哦