


' code is also relatively cheap, show me ur sense and thinking '
ResNets之前也用过很多,大概的思想也了解,觉得还是有必要读一下这篇上万引用的经典之作
Deep Residual Learning for Image Recognition
一句话总结:主要就是做了residual learning 以及 shotcut connection by identity来解决随着网络的加深,出现的退化现象
https://arxiv.org/pdf/1512.03385
1.Motivation
在一个深层次的卷积网络中,每一层学到的特征不尽相同且越深的部分学到的feature越细节。可以将其看成一个“蒸馏”的过程,越往后特征越“纯”(这里的纯我理解是更能详细的代表这个目标)。因此,人们认为网络越深,越强。
但是,随着网络的加深,出现了以下几个问题:
- 梯度消失/爆炸
- 过拟合
- 模型退化
前两个比较好理解,对于梯度消失/爆炸,网络更新是通过梯度的bp,也就是通过链式求导一个一个乘上去,如果里面都小于1,很多项之后就会趋于0,反之也好理解(当然这只是一种情况);对于第二个过拟合,就是网络层数增多之后,网络会变复杂,参数变多,如果数据量不能和这个匹配上就会出现过拟合,也就是说在训练集上过度学习和拟合,在测试集上缺少泛化能力。第三个这里要着重讲一下,是之前没有关注过的,叫做退化 ,情况如下图所示。
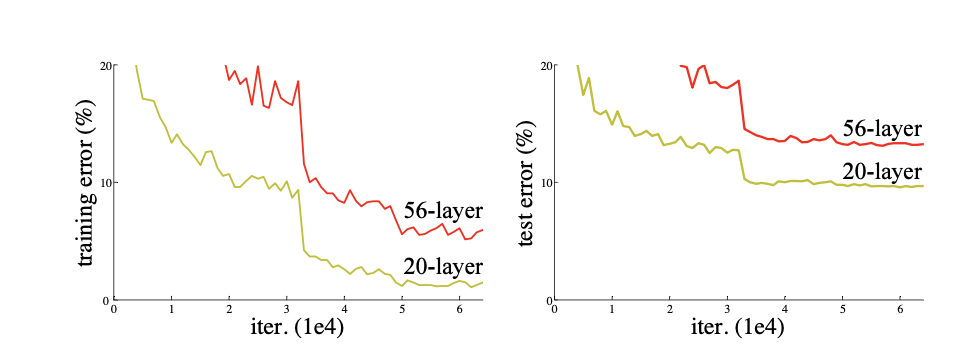
可以看到随着层数的增加,不仅test上的loss增加,train上的也增加,这就是degrade现象,区别于过拟合。
这里其中一部分原因,我觉得是经过很多层之后,有很多非线性的处理方法,会在整个过程中丢失一部分信息,这些信息丢失之后是不可逆的,所以才会使网络加深之后,会退化
因此,作者提出了一个ResNet,先放核心部分的结构,这张图也是很经典了,如下。
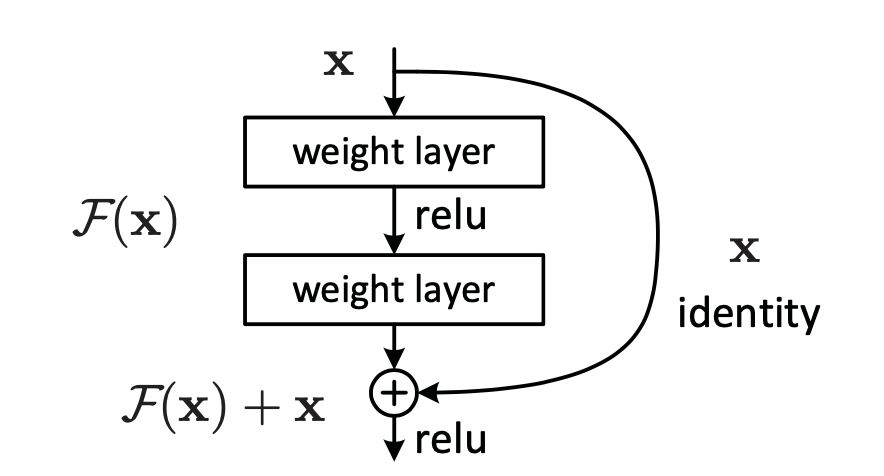
其中我们最初是拟合一个$\mathbf{H(x)}$,现在改为拟合一个$\mathbf{F(x)+x}$,即$\mathbf{F(x)=H(x)-x}$,具体的内容我们在下面章节再说。
2 两个核心问题
这部分介绍两个核心内容——residual learning以及shotcut connection
2.1 residual learning
首先有个假设:如果假设多个非线性层能够渐近一个复杂的函数,那么多个非线性层也一定可以渐近这个残差函数。
有了上面的假设,就可以解释第一部分为什么可以转化为拟合另外的问题了,即对于$\mathbf{H(x)}$的拟合和对于$\mathbf{F(x)+x}$可以近似,但是他俩的计算难度可能不一样。至于为什么我想了以下两个:
- 理解原文中提到,如果identity mapping是最优的,那么$\mathbf{F(x)}$是0,更好拟合;
- 知乎一些高赞提到,改为残差学习的方式之后,原本的映射会对输出的变化更加敏感;
- 另外经过求导可以发现,最后的式子中一部分因子是1+(带有参数的网络部分)也就是说,这部分几乎不会一直为0,所以梯度更新更顺畅。
另外,文中也提到
In real cases, it is unlikely that identity mappings are op- timal, but our reformulation may help to precondition the problem.
作者在之后的实验里也做了一些实验,讲了residual learning确实可以解决问题。
2.2 Identity Mapping by Shortcuts
直接上公式:
$\mathbf{y=F(,x)+x}$
其中$\mathbf{F(,x)}$为这一层或者这一部分学习的function,很好理解,后面$\mathbf{+x}$表示就是shortcuts的连接,这里是没有参数的,很简洁。这里没有加bias是作者认为在研究这个问题的时候可以先忽略不计。
这里需要注意的就是,后面加上的shortcut前面可以也加上对应的权重,但是经过实验,加上权重并不能让结果变好,因此,就算加权重,也是为了dimensions上的一致性。
这里肯定有人有一个思考,就是为什么就是简单的加一个x,不能是x/2之类的前面带有常数项系数的,这个是可以证明其必要性来来解决,~~由于这格式打公式真的不舒服,就介绍一下思路。~~算了,既然写blog了就把它写清楚吧!
$\mathbf{\lambdax+F(x,Wi)}$反向传播对这个进行链式求导,最后得出来的结果是:
- 如果$\lambda$大于1会爆炸;
- 小于1可能会发生梯度消失。
3 网络结构介绍
这一部分简单介绍resnets族的结构.
这一部分对于我来说就是熟悉一下resnet的一些结构,比如说你和别人介绍的时候总不能提出来个resnet15吧😄
实验网络结构如图(有点不想放,影响美观)
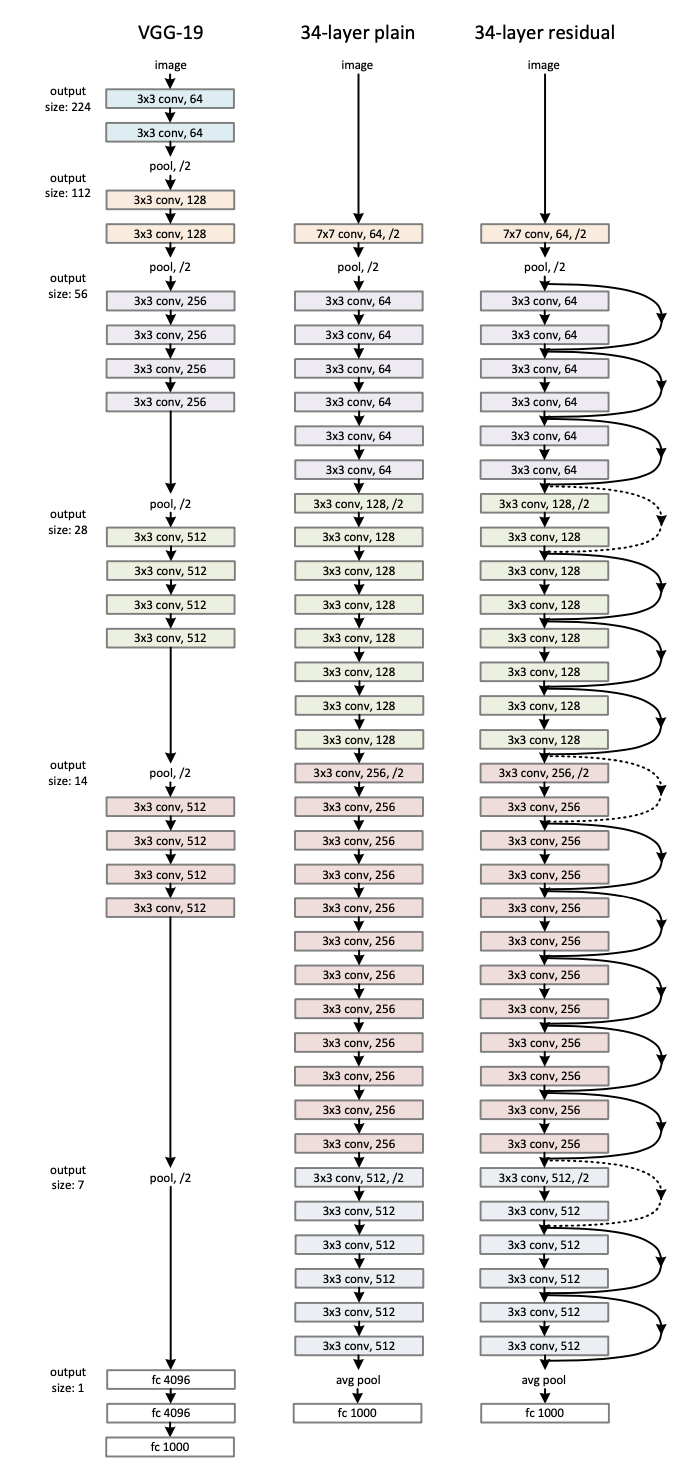
最初的版本是参考VGG网络,直接在其中加入residual block形成的,对于维度方面进行一定的处理,下面这张表可以解决我要的问题。
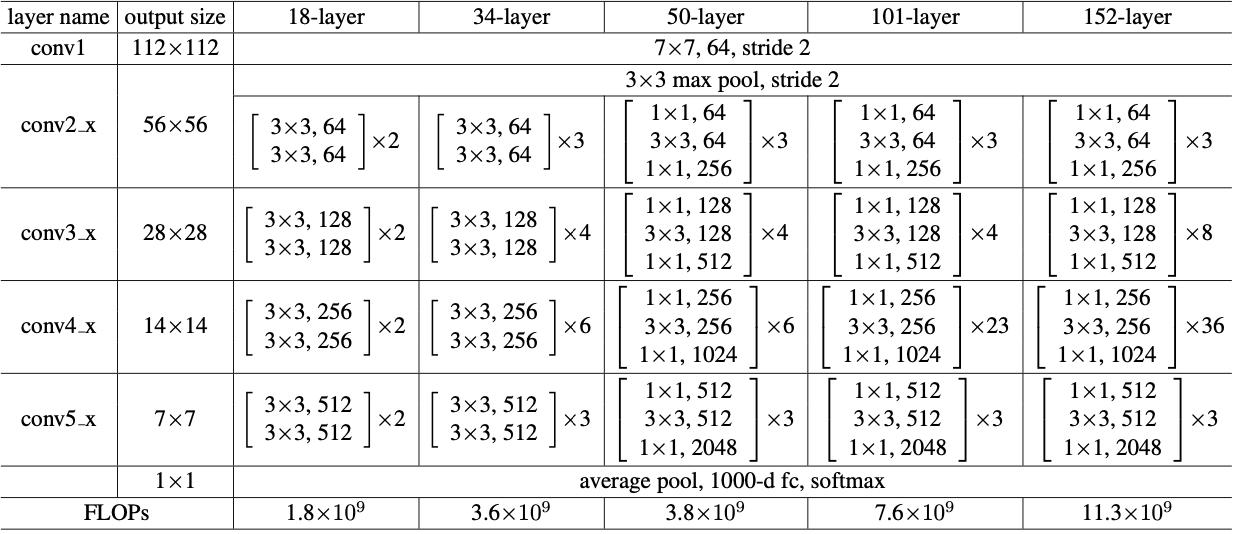
有了上面这个图,可以很清楚知道网络结构大概是什么样子的了!之后为了继续探索,网络加深的极限在哪里,作者对网络结构进行了改进,进一步减少了参数量,即用两个11和一个33去替换之前两个3*3.
4 总结
虽说之前经常用ResNets去做一些简单的任务,但是论文一直没有看过,这次又对网络的一些细节有了更好的理解(虽然还有些内容没有彻底理解透彻,但是比之前深的太多了),总结下来就是第二部分那两个方面,很好的解决了degrade、梯度以及一部分过拟合现象。
我觉得这篇文章好的点是在于,用一个很简洁的idea去解决问题,并取得了不错的结果,真的是很强,这也算是对自己在之后探索路上的一个引导,读这种经典的论文真的有意思嗷!
这种经典论文的讲解,网上多的很,自己的理解可能还有不到位的地方,如果有理解错的地方,欢迎留言提醒我哦