


Deep Label Distribution Learning
本篇论文是之前的LDL方法的改进版本,讲述了耿鑫老师在提出LDL算法之后又做了哪些工作,并分析了LDL在处理图像问题中遇到的一些问题,最后提出了DLDL算法。
有两篇相关论文,一个是对于DLDL定义讲述的论文,另一个是在Age Estimation任务上应用DLDL算法的论文,本篇博客将这两篇论文放在一起进行介绍
1、之前的LDL有什么问题
参考之前的博客,Label Distribution Learning 算法主要是将label转化为distribution的形式来避免标签中存在ambiguity的问题。但是经过分析可以得知,这样做只是在classification阶段做了一些标签上的优化,拿计算机视觉中最常见的分类任务举例,此类任务一般先对图像中的特征进行提取,之后再用各种各样的分类器得出最后的结果。如果运用LDL也就是说只是在一个网络head的部分,针对标签进行了优化,在图像特征提取阶段没有什么作为
那么 问题不就出现了嘛!在图像提取的过程中并没有进行一些优化
2、DLDL是怎么做的
那么我们可以将Conv层来提特征,然后将特征输出到对应的维度之后,再用Softmax将其转化为和为1的形式之后,再使用LDL,使用KL散度作为优化器对整个网络进行训练,最后得到较好的结果。
所以再梳理一遍流程:
使用比较经典的Conv来提取网络的特征,最后FC层直接映射到需要的维度上,例如预测0-100岁,那么最后输出的维度就是101维。使用Softmax作为activate function来对结果进行处理,将其处理为和为1的且都是正数的类型。这个输出可以作为预测的label distribution(这个我终于懂了,哦吼!)。接着和gts进行比较,使用的是KL散度进行优化,之后就不停迭代训练了呗。
3、DLDL V1存在什么问题
还是拿年龄预测问题来举例,我们最后想要的输出肯定是一个确定的离散的数值,比如22,23。但是在第一版中,DLDL的优化是针对Label Distribution进行的,但是最后我们想要的输出确实一个确定的值,第二篇论文中认为这是存在一些前后不协调的矛盾的,因此还需要对此进行优化
4、DLDL V2干了些什么
在后续的第二个版本中为了解决第三节中提到的问题,就是很简单的将其转化成了一个多任务的问题,在计算loss的过程中也是使用多个loss进行计算,例如,用KL Loss来计算两个概率分布之间的不同,在最后用MAE计算两个年龄之间的loss,将两者相加求最后的Loss进行梯度更新迭代。针对年龄估计,V2网络结构如图1所示
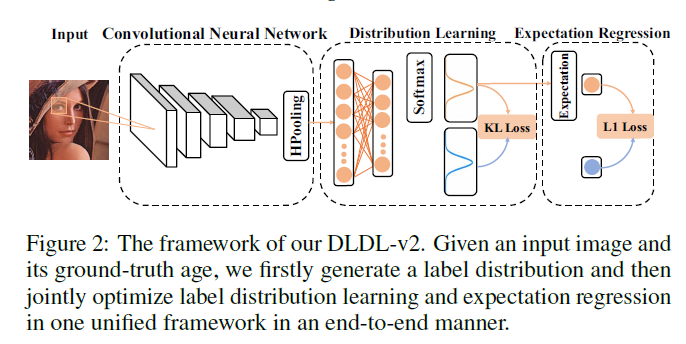
图 1
5、总结
这两篇论文总的来说都是在之前LDL的基础上结合现有的成果做了一些改进,第二篇论文中另一个有价值的点我认为是对ranking的方法以及DLDL的方法进行了较深层次的分析,最后得出来的结论是两者都是将label转化为一种分布,只是形式不同。
毕设中计划将用第二篇论文中的网络,另外,为了解决long tail问题,接下来一周计划阅读一些有关长尾数据处理的文章,最后结合一下跑一下看看效果。