


最近在复习机器学习的有关内容,看到聚类这部分想到之前没做过实际的案例,就找了个有关超市的分析做了一下,but收获最大的还是发现sns原来可以画这么好看的图
1、案例介绍
这个案例就是提供顾客年龄、年收入、性别以及超市对其消费能力的评估分数,来分析应该给哪一类人推销。
2、数据可视化
这部分虽然很简单,但是之前画图都草草了事,没想到用sns能画出来这么精美的图。
主要用的就是matplotlib以及seaborn(sns),后者是对前者的一个升级版本,有很多封装好的漂亮的图模板。
2.1 年收入以及年龄分布
def show_figure():
plt.rcParams['figure.figsize'] = (16, 6)
# 一副图有俩子图,参数含义:(行,列,index)
plt.subplot(1, 2, 1)
# sns是对matplotlib的高级封装可以有更多的样式
sns.set(style = 'whitegrid')
sns.distplot(data['Annual Income (k$)'])
plt.title('Distribution of Annual Income', fontsize = 20)
plt.xlabel('Range of Annual Income')
plt.ylabel('Count')
plt.subplot(1, 2, 2)
sns.set(style = 'whitegrid')
sns.distplot(data['Age'], color = 'red')
plt.title('Distribution of Age', fontsize = 20)
plt.xlabel('Range of Age')
plt.ylabel('Count')
plt.show()
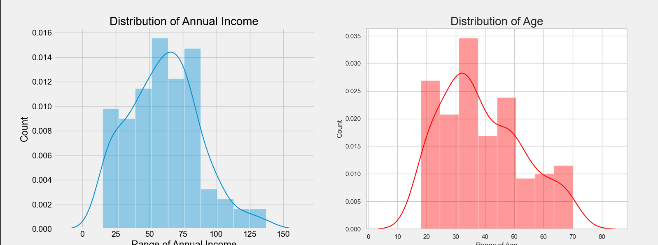
可以看出年收入多集中在中间的部分,年龄同样也是。
2.2 年龄分布饼图
def analyse_gender():
labels = ['Female', 'Male']
size = data['Gender'].value_counts()
colors = ['lightgreen', 'orange']
explode = [0, 0.1]
plt.rcParams['figure.figsize'] = (6, 6)
plt.pie(size, colors=colors, explode=explode,
labels=labels, shadow=True, autopct='%.2f%%')
plt.title('Gender', fontsize=20)
plt.axis('off')
plt.legend()
plt.show()
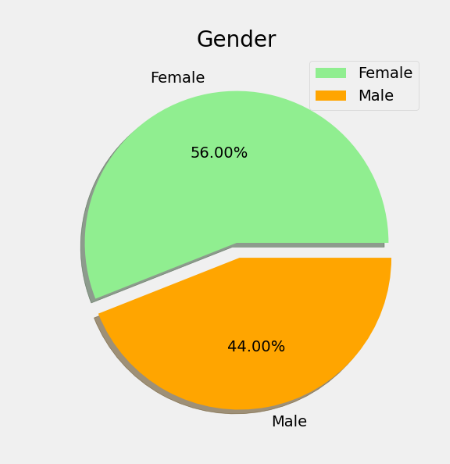
在男性数量多于女性的情况下,女性购物的占比较大,可以初步得出女性更喜欢购物。
2.3 年龄以、年收入以及购物的得分分布
def show_distri_age():
plt.rcParams['figure.figsize'] = (12, 4)
sns.countplot(data['Age'], palette='hsv')
plt.title('Distribution of Age', fontsize=20)
plt.show()
def show_dietri_annual_income():
plt.rcParams['figure.figsize'] = (12, 4)
sns.countplot(data['Annual Income (k$)'], palette='hsv')
plt.title('Distribution of Annual Income')
plt.show()
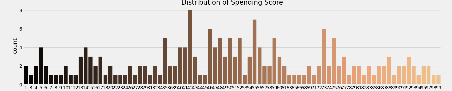
def show_distri_score():
plt.rcParams['figure.figsize'] = (20, 4)
sns.countplot(data['Spending Score (1-100)'], palette='copper')
plt.title('Distribution of Spending Score', fontsize=20)
plt.show()
图像分别如下
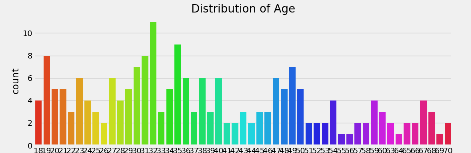
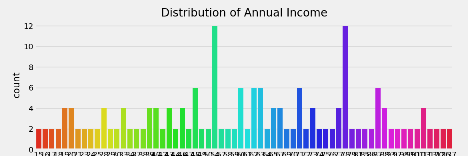
2.4 各个属性之间的关系图像
sns.pairplot(data)
plt.title('Pairplot for the Data', fontsize = 20)
plt.show()
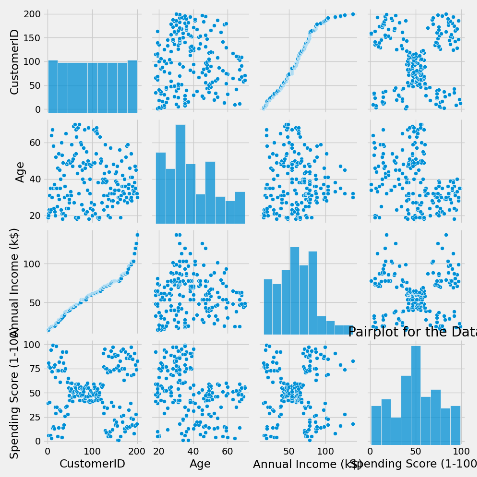
对角线上的图像是分布直方图,其他位置是对应两个属性的关系散点图
2.5 hitmap
def show_heat_map():
plt.rcParams['figure.figsize'] = (12, 4)
sns.heatmap(data.corr(), cmap='Wistia', annot=True)
plt.title('Heatmap for the Data', fontsize=20)
plt.show()
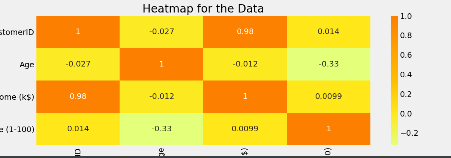
3、聚类分析
接下来开始聚类,首先确定k的选值,使用EM的思想进行试验,当k远小于子类数的时候,k增大一个,wcss曲线下降较大,接近就趋于平缓,根据这个来确定较好的k值。
def get_best_k():
x = data.iloc[:, [3, 4]].values
wcss = []
for i in range(1, 10):
km = KMeans(n_clusters=i, init='k-means++', max_iter=200,
n_init=10, random_state=0)
km.fit((x))
wcss.append(km.inertia_)
plt.plot(range(1, 10), wcss)
plt.title('EM', fontsize=10)
plt.xlabel('k')
plt.ylabel('wcss')
plt.show()
图像如下
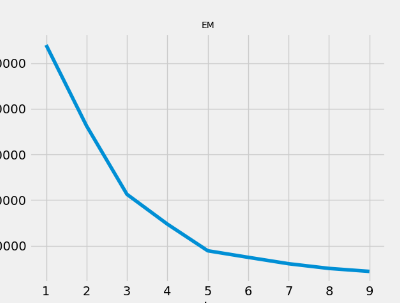
因此我们把k设置在5来进行分析
km = KMeans(n_clusters=5, init='k-means++', max_iter=300, n_init=10, random_state=0)
x = data.iloc[:, [3, 4]].values
y_means = km.fit_predict(x)
test = x[y_means == 0, 0]
plt.scatter(x[y_means == 0, 0], x[y_means == 0, 1], s=100,
c='pink', label='miser')
plt.scatter(x[y_means == 1, 0], x[y_means == 1, 1], s=100,
c='yellow', label='general')
plt.scatter(x[y_means == 2, 0], x[y_means == 2, 1], s=100,
c='cyan', label='target')
plt.scatter(x[y_means == 3, 0], x[y_means == 3, 1], s=100,
c='magenta', label='spendthrift')
plt.scatter(x[y_means == 4, 0], x[y_means == 4, 1], s=100,
c='orange', label='careful')
plt.scatter(km.cluster_centers_[:, 0], km.cluster_centers_[:, 1],
s=50, c='blue', label='centeroid')
plt.style.use('fivethirtyeight')
plt.title('K Means Clustering', fontsize=20)
plt.xlabel('Annual Income')
plt.ylabel('Spending Score')
plt.legend()
plt.grid()
plt.show()
聚类结果如下
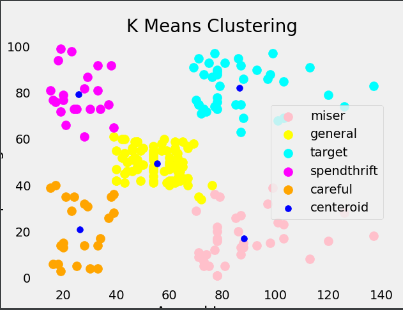
其中target代表的就是我们要进行推销的目标用户。