

Pytorch GPU并行训练
在深度学习模型训练的过程中,如果你有一张不错的GPU计算卡,那么你的训练速度将会快很多,如果你有很多张卡,那么你就可以在同样的时间里,迭代更多个版本的模型,这也就离高级调参侠不远了。
使用单张卡进行训练的操作十分简单,这篇文章就主要介绍一下单机多卡训练的一些内容,主要包括并行的基本原理,并行的算法及其背后的原理,最后将会介绍Pytorch中的两个API来帮助我们完成并行计算。
1、基础理论
首先我们来说一下并行计算的分类:
- 数据并行/模型并行【按照并行方式分类】
- 同步更新/异步更新【按照更新方式分类】
接下来将逐一介绍
数据并行 vs. 模型并行
- 数据并行:每个GPU上的模型是相同的,但是喂给模型的数据不同;
- 模型并行:每个GPU上的数据相同,但是跑的是整个模型的不同部分,比如深度模型中的某些层。
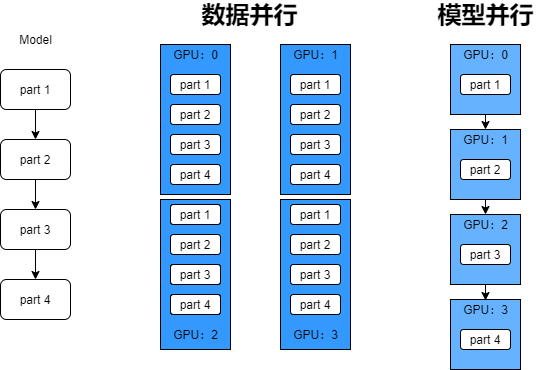
从上图中可以很明显看到数据并行和模型并行的差别,当我们的模型非常大的时候,可以将模型的不同部分放在不同的gpu上,但是这样的话,设备间的要进行大量的通信交换数据,可能也会损失一些性能。数据并行的话,用的还是更多一些的。
同步 vs. 异步
- 同步更新:等所有机器都算完一个step,把数值加起来,一起运算;
- 异步更新:每一个机器算完一个step之后,不用等别人,直接自己更新。
所以同步更新计算的速度其实取决于最慢的那个机器的更新速度。这样看来异步更新其实要更好一点,但其中会涉及很多比较复杂的控制逻辑,一般也常用同步更新的方式。
2、数据并行的两种方式
- Parameter Server:GPU0将数据分发给剩下的机器,拿到数据的机器分别计算,计算之后,再汇总到GPU0进行运算,计算结果,更新的一些信息再由GPU0分发给其余的机器;
- Ring AllReduce:类似于一个环形,第一轮传递传递以下数值,这样可以累加起来,第二轮就是用最后累加的数据进行更新。
从定义上可以看出,Parameter Server,会对这个GPU0造成很大的负担,另外消耗的时间成本和机器数量线性相关增长;另外一种方式,通过一个环形结构,更好的做到了负载均衡,而且当机器数量很多的时候,整个消耗的时间成本将近似的去除机器数量的影响。
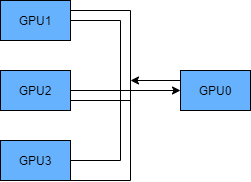
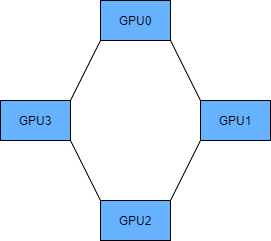
3、Pytorch中的API
- DataParallel(DP):Parameter Server模式,一张卡为reducer,实现也超级简单,一行代码。
- DistributedDataParallel(DDP):All-Reduce模式,本意是用来分布式训练,但是也可用于单机多卡。
主要就是这两种方式,下面将以代码形式演示
# DataParallel
import torch
import torch.nn as nn
class model(nn.Module):
def __init__(self):
super(model, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
output = self.fc(x)
return output
net = model()
net.cuda()#先将模型放在cuda上,这里默认放在cuda0
net.DataParallel().cuda()#就这一句话就欧克了
第二种方式相对繁琐一点
#1)初始化这里用nccl后端
torch.distributed.init_process_group(backend="nccl")
#2)为每个进程配置
local_rank = torch.distributed.get_rank()
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
#3)在数据处理部分用sampler
rand_loader = DataLoader(dataset=dataset,
batch_size=batch_size,
sampler=DistributedSampler(dataset))
#4)模型处理一波
model.to(device)
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[local_rank],
output_devie=local_rank)
这篇博客的内容就是这样了,平常多积累,机会来了才能做好准备,共勉。